搜索到
144
篇与
的结果
-
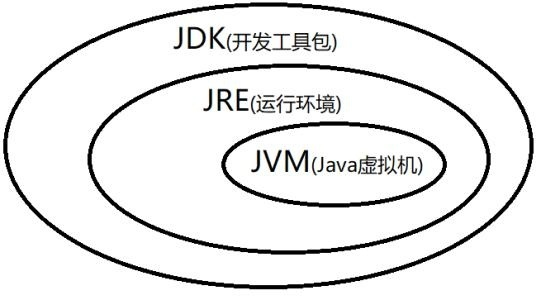
 Java基础概念与常识 Java 语言有哪些特点?简单易学;面向对象(封装,继承,多态);平台无关性( Java 虚拟机实现平台无关性);支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);可靠性;安全性;支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);编译与解释并存;JVM vs JDK vs JREJVMJava 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。什么是字节码?采用字节码的好处是什么?在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。Java 程序从源代码到运行一般有下面 3 步:我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。总结:Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。JDK 和 JREJDK 是 Java Development Kit 缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装 JDK 了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何 Java 开发,仍然需要安装 JDK。例如,如果要使用 JSP 部署 Web 应用程序,那么从技术上讲,您只是在应用程序服务器中运行 Java 程序。那你为什么需要 JDK 呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。为什么说 Java 语言“编译与解释并存”?高级编程语言按照程序的执行方式分为编译型和解释型两种。简单来说,编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。比如,你想阅读一本英文名著,你可以找一个英文翻译人员帮助你阅读,有两种选择方式,你可以先等翻译人员将全本的英文名著(也就是源码)都翻译成汉语,再去阅读,也可以让翻译人员翻译一段,你在旁边阅读一段,慢慢把书读完。Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(\*.class 文件),这种字节码必须由 Java 解释器来解释执行。因此,我们可以认为 Java 语言编译与解释并存。Oracle JDK 和 OpenJDK 的对比可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么 Oracle 和 OpenJDK 之间是否存在重大差异?下面我通过收集到的一些资料,为你解答这个被很多人忽视的问题。对于 Java 7,没什么关键的地方。OpenJDK 项目主要基于 Sun 捐赠的 HotSpot 源代码。此外,OpenJDK 被选为 Java 7 的参考实现,由 Oracle 工程师维护。关于 JVM,JDK,JRE 和 OpenJDK 之间的区别,Oracle 博客帖子在 2012 年有一个更详细的答案:问:OpenJDK 存储库中的源代码与用于构建 Oracle JDK 的代码之间有什么区别?答:非常接近 - 我们的 Oracle JDK 版本构建过程基于 OpenJDK 7 构建,只添加了几个部分,例如部署代码,其中包括 Oracle 的 Java 插件和 Java WebStart 的实现,以及一些封闭的源代码派对组件,如图形光栅化器,一些开源的第三方组件,如 Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源 Oracle JDK 的所有部分,除了我们考虑商业功能的部分。总结:Oracle JDK 大概每 6 个月发一次主要版本,而 OpenJDK 版本大概每三个月发布一次。但这不是固定的,我觉得了解这个没啥用处。详情参见:https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-release-cadence 。OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是 OpenJDK 的一个实现,并不是完全开源的;Oracle JDK 比 OpenJDK 更稳定。OpenJDK 和 Oracle JDK 的代码几乎相同,但 Oracle JDK 有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择 Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用 OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到 Oracle JDK 就可以解决问题;在响应性和 JVM 性能方面,Oracle JDK 与 OpenJDK 相比提供了更好的性能;Oracle JDK 不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 根据 GPL v2 许可获得许可。Java 和 C++的区别?我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过 C++,也要记下来!都是面向对象的语言,都支持封装、继承和多态Java 不提供指针来直接访问内存,程序内存更加安全Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。......import java 和 javax 有什么区别?刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准 API 的一部分。所以,实际上 java 和 javax 没有区别。这都是一个名字。基本语法字符型常量和字符串常量的区别?形式 : 字符常量是单引号引起的一个字符,字符串常量是双引号引起的 0 个或若干个字符含义 : 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)占内存大小 : 字符常量只占 2 个字节; 字符串常量占若干个字节 (注意: char 在 Java 中占两个字节),字符封装类 Character 有一个成员常量 Character.SIZE 值为 16,单位是bits,该值除以 8(1byte=8bits)后就可以得到 2 个字节java 编程思想第四版:2.2.2 节注释Java 中的注释有三种:单行注释多行注释文档注释。在我们编写代码的时候,如果代码量比较少,我们自己或者团队其他成员还可以很轻易地看懂代码,但是当项目结构一旦复杂起来,我们就需要用到注释了。注释并不会执行(编译器在编译代码之前会把代码中的所有注释抹掉,字节码中不保留注释),是我们程序员写给自己看的,注释是你的代码说明书,能够帮助看代码的人快速地理清代码之间的逻辑关系。因此,在写程序的时候随手加上注释是一个非常好的习惯。《Clean Code》这本书明确指出:代码的注释不是越详细越好。实际上好的代码本身就是注释,我们要尽量规范和美化自己的代码来减少不必要的注释。若编程语言足够有表达力,就不需要注释,尽量通过代码来阐述。举个例子:去掉下面复杂的注释,只需要创建一个与注释所言同一事物的函数即可// check to see if the employee is eligible for full benefits if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))应替换为if (employee.isEligibleForFullBenefits())标识符和关键字的区别是什么?在我们编写程序的时候,需要大量地为程序、类、变量、方法等取名字,于是就有了标识符,简单来说,标识符就是一个名字。但是有一些标识符,Java 语言已经赋予了其特殊的含义,只能用于特定的地方,这种特殊的标识符就是关键字。因此,关键字是被赋予特殊含义的标识符。比如,在我们的日常生活中 ,“警察局”这个名字已经被赋予了特殊的含义,所以如果你开一家店,店的名字不能叫“警察局”,“警察局”就是我们日常生活中的关键字。Java 中有哪些常见的关键字?访问控制privateprotectedpublic 类,方法和变量修饰符abstractclassextendsfinalimplementsinterfacenative newstaticstrictfpsynchronizedtransientvolatile 程序控制breakcontinuereturndowhileifelse forinstanceofswitchcasedefault 错误处理trycatchthrowthrowsfinally 包相关importpackage 基本类型booleanbytechardoublefloatintlong shortnulltruefalse 变量引用superthisvoid 保留字gotoconst 自增自减运算符在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1,Java 提供了一种特殊的运算符,用于这种表达式,叫做自增运算符(++)和自减运算符(--)。++和--运算符可以放在变量之前,也可以放在变量之后,当运算符放在变量之前时(前缀),先自增/减,再赋值;当运算符放在变量之后时(后缀),先赋值,再自增/减。例如,当 b = ++a 时,先自增(自己增加 1),再赋值(赋值给 b);当 b = a++ 时,先赋值(赋值给 b),再自增(自己增加 1)。也就是,++a 输出的是 a+1 的值,a++输出的是 a 值。用一句口诀就是:“符号在前就先加/减,符号在后就后加/减”。continue、break、和 return 的区别是什么?在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词:continue :指跳出当前的这一次循环,继续下一次循环。break :指跳出整个循环体,继续执行循环下面的语句。return 用于跳出所在方法,结束该方法的运行。return 一般有两种用法:return; :直接使用 return 结束方法执行,用于没有返回值函数的方法return value; :return 一个特定值,用于有返回值函数的方法Java 泛型了解么?什么是类型擦除?介绍一下常用的通配符?Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的泛型信息都会被擦掉,这也就是通常所说类型擦除 。List<Integer> list = new ArrayList<>(); list.add(12); //这里直接添加会报错 list.add("a"); Class<? extends List> clazz = list.getClass(); Method add = clazz.getDeclaredMethod("add", Object.class); //但是通过反射添加,是可以的 add.invoke(list, "kl"); System.out.println(list);泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。1.泛型类://此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型 //在实例化泛型类时,必须指定T的具体类型 public class Generic<T> { private T key; public Generic(T key) { this.key = key; } public T getKey() { return key; } }如何实例化泛型类:Generic<Integer> genericInteger = new Generic<Integer>(123456);2.泛型接口 :public interface Generator<T> { public T method(); }实现泛型接口,不指定类型:class GeneratorImpl<T> implements Generator<T>{ @Override public T method() { return null; } }实现泛型接口,指定类型:class GeneratorImpl implements Generator<String>{ @Override public String method() { return "hello"; } }3.泛型方法 :public static <E> void printArray(E[] inputArray) { for (E element : inputArray) { System.out.printf("%s ", element); } System.out.println(); }使用:// 创建不同类型数组: Integer, Double 和 Character Integer[] intArray = { 1, 2, 3 }; String[] stringArray = { "Hello", "World" }; printArray(intArray); printArray(stringArray);常用的通配符为: T,E,K,V,?? 表示不确定的 java 类型T (type) 表示具体的一个 java 类型K V (key value) 分别代表 java 键值中的 Key ValueE (element) 代表 Element==和 equals 的区别对于基本数据类型来说,==比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。equals() 作用不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。equals()方法存在于Object类中,而Object类是所有类的直接或间接父类。Object 类 equals() 方法:public boolean equals(Object obj) { return (this == obj); }equals() 方法存在两种使用情况:类没有覆盖 equals()方法 :通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是 Object类equals()方法。类覆盖了 equals()方法 :一般我们都覆盖 equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。举个例子:public class test1 { public static void main(String[] args) { String a = new String("ab"); // a 为一个引用 String b = new String("ab"); // b为另一个引用,对象的内容一样 String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 if (aa == bb) // true System.out.println("aa==bb"); if (a == b) // false,非同一对象 System.out.println("a==b"); if (a.equals(b)) // true System.out.println("aEQb"); if (42 == 42.0) { // true System.out.println("true"); } } }说明:String 中的 equals 方法是被重写过的,因为 Object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。String类equals()方法:public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }hashCode()与 equals()面试官可能会问你:“你重写过 hashcode 和 equals么,为什么重写 equals 时必须重写 hashCode 方法?”1)hashCode()介绍:hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。public native int hashCode();散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)2)为什么要有 hashCode?我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode?当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals() 方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head First Java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。3)为什么重写 equals 时必须重写 hashCode 方法?如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖。hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)4)为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。因为 hashCode() 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode。我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。更多关于 hashcode() 和 equals() 的内容可以查看:Java hashCode() 和 equals()的若干问题解答基本数据类型Java 中的几种基本数据类型是什么?对应的包装类型是什么?各自占用多少字节呢?Java 中有 8 种基本数据类型,分别为:6 种数字类型 :byte、short、int、long、float、double1 种字符类型:char1 种布尔型:boolean。这 8 种基本数据类型的默认值以及所占空间的大小如下:基本类型位数字节默认值int3240short1620long6480Lbyte810char162'u0000'float3240fdouble6480dboolean1 false另外,对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。注意:Java 里使用 long 类型的数据一定要在数值后面加上 L,否则将作为整型解析。char a = 'h'char :单引号,String a = "hello" :双引号。这八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean 。包装类型不赋值就是 Null ,而基本类型有默认值且不是 Null。另外,这个问题建议还可以先从 JVM 层面来分析。基本数据类型直接存放在 Java 虚拟机栈中的局部变量表中,而包装类型属于对象类型,我们知道对象实例都存在于堆中。相比于对象类型, 基本数据类型占用的空间非常小。《深入理解 Java 虚拟机》 :局部变量表主要存放了编译期可知的基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。自动装箱与拆箱装箱:将基本类型用它们对应的引用类型包装起来;拆箱:将包装类型转换为基本数据类型;举例:Integer i = 10; //装箱 int n = i; //拆箱上面这两行代码对应的字节码为: L1 LINENUMBER 8 L1 ALOAD 0 BIPUSH 10 INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer; PUTFIELD AutoBoxTest.i : Ljava/lang/Integer; L2 LINENUMBER 9 L2 ALOAD 0 ALOAD 0 GETFIELD AutoBoxTest.i : Ljava/lang/Integer; INVOKEVIRTUAL java/lang/Integer.intValue ()I PUTFIELD AutoBoxTest.n : I RETURN从字节码中,我们发现装箱其实就是调用了 包装类的valueOf()方法,拆箱其实就是调用了 xxxValue()方法。因此,Integer i = 10 等价于 Integer i = Integer.valueOf(10)int n = i 等价于 int n = i.intValue();8 种基本类型的包装类和常量池Java 基本类型的包装类的大部分都实现了常量池技术。Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在[0,127]范围的缓存数据,Boolean 直接返回 True Or False。Integer 缓存源码:/** *此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。 */ public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); } private static class IntegerCache { static final int low = -128; static final int high; static final Integer cache[]; }Character 缓存源码:public static Character valueOf(char c) { if (c <= 127) { // must cache return CharacterCache.cache[(int)c]; } return new Character(c); } private static class CharacterCache { private CharacterCache(){} static final Character cache[] = new Character[127 + 1]; static { for (int i = 0; i < cache.length; i++) cache[i] = new Character((char)i); } }Boolean 缓存源码:public static Boolean valueOf(boolean b) { return (b ? TRUE : FALSE); }如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。Integer i1 = 33; Integer i2 = 33; System.out.println(i1 == i2);// 输出 true Float i11 = 333f; Float i22 = 333f; System.out.println(i11 == i22);// 输出 false Double i3 = 1.2; Double i4 = 1.2; System.out.println(i3 == i4);// 输出 false下面我们来看一下问题。下面的代码的输出结果是 true 还是 flase 呢?Integer i1 = 40; Integer i2 = new Integer(40); System.out.println(i1==i2);Integer i1=40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1=Integer.valueOf(40) 。因此,i1 直接使用的是常量池中的对象。而Integer i1 = new Integer(40) 会直接创建新的对象。因此,答案是 false 。你答对了吗?记住:所有整型包装类对象之间值的比较,全部使用 equals 方法比较。方法(函数)什么是方法的返回值?方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用是接收出结果,使得它可以用于其他的操作!方法有哪几种类型?1.无参数无返回值的方法// 无参数无返回值的方法(如果方法没有返回值,不能不写,必须写void,表示没有返回值) public void f1() { System.out.println("无参数无返回值的方法"); }2.有参数无返回值的方法/** * 有参数无返回值的方法 * 参数列表由零组到多组“参数类型+形参名”组合而成,多组参数之间以英文逗号(,)隔开,形参类型和形参名之间以英文空格隔开 */ public void f2(int a, String b, int c) { System.out.println(a + "-->" + b + "-->" + c); }3.有返回值无参数的方法// 有返回值无参数的方法(返回值可以是任意的类型,在函数里面必须有return关键字返回对应的类型) public int f3() { System.out.println("有返回值无参数的方法"); return 2; }4.有返回值有参数的方法// 有返回值有参数的方法 public int f4(int a, int b) { return a * b; }5.return 在无返回值方法的特殊使用// return在无返回值方法的特殊使用 public void f5(int a) { if (a > 10) { return;//表示结束所在方法 (f5方法)的执行,下方的输出语句不会执行 } System.out.println(a); }在一个静态方法内调用一个非静态成员为什么是非法的?这个需要结合 JVM 的相关知识,静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,然后通过类的实例对象去访问。在类的非静态成员不存在的时候静态成员就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。静态方法和实例方法有何不同?在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。为什么 Java 中只有值传递?首先,我们回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。按值调用(call by value) 表示方法接收的是调用者提供的值,按引用调用(call by reference) 表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。下面通过 3 个例子来给大家说明example 1public static void main(String[] args) { int num1 = 10; int num2 = 20; swap(num1, num2); System.out.println("num1 = " + num1); System.out.println("num2 = " + num2); } public static void swap(int a, int b) { int temp = a; a = b; b = temp; System.out.println("a = " + a); System.out.println("b = " + b); }结果:a = 20 b = 10 num1 = 10 num2 = 20解析:在 swap 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 中的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.example 2 public static void main(String[] args) { int[] arr = { 1, 2, 3, 4, 5 }; System.out.println(arr[0]); change(arr); System.out.println(arr[0]); } public static void change(int[] array) { // 将数组的第一个元素变为0 array[0] = 0; }结果:1 0解析:array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的是同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。很多程序设计语言(特别是,C++和 Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为 Java 程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。example 3public class Test { public static void main(String[] args) { // TODO Auto-generated method stub Student s1 = new Student("小张"); Student s2 = new Student("小李"); Test.swap(s1, s2); System.out.println("s1:" + s1.getName()); System.out.println("s2:" + s2.getName()); } public static void swap(Student x, Student y) { Student temp = x; x = y; y = temp; System.out.println("x:" + x.getName()); System.out.println("y:" + y.getName()); } }结果:x:小李 y:小张 s1:小张 s2:小李解析:交换之前:交换之后:通过上面两张图可以很清晰的看出: 方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap 方法的参数 x 和 y 被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝总结Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按值传递的。下面再总结一下 Java 中方法参数的使用情况:一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。一个方法可以改变一个对象参数的状态。一个方法不能让对象参数引用一个新的对象。参考:《Java 核心技术卷 Ⅰ》基础知识第十版第四章 4.5 小节重载和重写的区别重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法重载发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。下面是《Java 核心技术》对重载这个概念的介绍:综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。重写重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。返回值类型、方法名、参数列表必须相同,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。如果父类方法访问修饰符为 private/final/static 则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。构造方法无法被重写综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变暖心的 Guide 哥最后再来个图表总结一下!区别点重载方法重写方法发生范围同一个类子类参数列表必须修改一定不能修改返回类型可修改子类方法返回值类型应比父类方法返回值类型更小或相等异常可修改子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;访问修饰符可修改一定不能做更严格的限制(可以降低限制)发生阶段编译期运行期方法的重写要遵循“两同两小一大”(以下内容摘录自《疯狂 Java 讲义》,issue#892 ):“两同”即方法名相同、形参列表相同;“两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;“一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。⭐️ 关于 重写的返回值类型 这里需要额外多说明一下,上面的表述不太清晰准确:如果方法的返回类型是 void 和基本数据类型,则返回值重写时不可修改。但是如果方法的返回值是引用类型,重写时是可以返回该引用类型的子类的。public class Hero { public String name() { return "超级英雄"; } } public class SuperMan extends Hero{ @Override public String name() { return "超人"; } public Hero hero() { return new Hero(); } } public class SuperSuperMan extends SuperMan { public String name() { return "超级超级英雄"; } @Override public SuperMan hero() { return new SuperMan(); } }深拷贝 vs 浅拷贝浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。Java 面向对象面向对象和面向过程的区别面向过程 :面向过程性能比面向对象高。 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix 等一般采用面向过程开发。但是,面向过程没有面向对象易维护、易复用、易扩展。面向对象 :面向对象易维护、易复用、易扩展。 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,面向对象性能比面向过程低。参见 issue : 面向过程 :面向过程性能比面向对象高??这个并不是根本原因,面向过程也需要分配内存,计算内存偏移量,Java 性能差的主要原因并不是因为它是面向对象语言,而是 Java 是半编译语言,最终的执行代码并不是可以直接被 CPU 执行的二进制机械码。而面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比 Java 好。成员变量与局部变量的区别有哪些?从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。从变量在内存中的存储方式来看,如果成员变量是使用 static 修饰的,那么这个成员变量是属于类的,如果没有使用 static 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。从变量是否有默认值来看,成员变量如果没有被赋初,则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。创建一个对象用什么运算符?对象实体与对象引用有何不同?new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向 0 个或 1 个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有 n 个引用指向它(可以用 n 条绳子系住一个气球)。对象的相等与指向他们的引用相等,两者有什么不同?对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?构造方法主要作用是完成对类对象的初始化工作。如果一个类没有声明构造方法,也可以执行!因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法了,这时候,就不能直接 new 一个对象而不传递参数了,所以我们一直在不知不觉地使用构造方法,这也是为什么我们在创建对象的时候后面要加一个括号(因为要调用无参的构造方法)。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。构造方法有哪些特点?是否可被 override?特点:名字与类名相同。没有返回值,但不能用 void 声明构造函数。生成类的对象时自动执行,无需调用。构造方法不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。面向对象三大特征封装封装是指把一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。就好像我们看不到挂在墙上的空调的内部的零件信息(也就是属性),但是可以通过遥控器(方法)来控制空调。如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。就好像如果没有空调遥控器,那么我们就无法操控空凋制冷,空调本身就没有意义了(当然现在还有很多其他方法 ,这里只是为了举例子)。public class Student { private int id;//id属性私有化 private String name;//name属性私有化 //获取id的方法 public int getId() { return id; } //设置id的方法 public void setId(int id) { this.id = id; } //获取name的方法 public String getName() { return name; } //设置name的方法 public void setName(String name) { this.name = name; } }继承不同类型的对象,相互之间经常有一定数量的共同点。例如,小明同学、小红同学、小李同学,都共享学生的特性(班级、学号等)。同时,每一个对象还定义了额外的特性使得他们与众不同。例如小明的数学比较好,小红的性格惹人喜爱;小李的力气比较大。继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承,可以快速地创建新的类,可以提高代码的重用,程序的可维护性,节省大量创建新类的时间 ,提高我们的开发效率。关于继承如下 3 点请记住:子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。子类可以拥有自己属性和方法,即子类可以对父类进行扩展。子类可以用自己的方式实现父类的方法。(以后介绍)。多态多态,顾名思义,表示一个对象具有多种的状态。具体表现为父类的引用指向子类的实例。多态的特点:对象类型和引用类型之间具有继承(类)/实现(接口)的关系;引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定;多态不能调用“只在子类存在但在父类不存在”的方法;如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?可变性简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以String 对象是不可变的。补充(来自issue 675):在 Java 9 之后,String 、StringBuilder 与 StringBuffer 的实现改用 byte 数组存储字符串 private final byte[] value而 StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是AbstractStringBuilder 实现的,大家可以自行查阅源码。AbstractStringBuilder.javaabstract class AbstractStringBuilder implements Appendable, CharSequence { /** * The value is used for character storage. */ char[] value; /** * The count is the number of characters used. */ int count; AbstractStringBuilder(int capacity) { value = new char[capacity]; }}线程安全性String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。性能每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。对于三者使用的总结:操作少量的数据: 适用 String单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder多线程操作字符串缓冲区下操作大量数据: 适用 StringBufferObject 类的常见方法总结Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。 public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。 public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。 protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。 public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。 public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。 public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。 public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。 public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。 public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念 protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作反射何为反射?如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。反射机制优缺点优点 : 可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利缺点 :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。Java Reflection: Why is it so slow?反射的应用场景像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 Method 来调用指定的方法。public class DebugInvocationHandler implements InvocationHandler { /** * 代理类中的真实对象 */ private final Object target; public DebugInvocationHandler(Object target) { this.target = target; } public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException { System.out.println("before method " + method.getName()); Object result = method.invoke(target, args); System.out.println("after method " + method.getName()); return result; } } 另外,像 Java 中的一大利器 注解 的实现也用到了反射。为什么你使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。异常Java 异常类层次结构图图片来自:https://simplesnippets.tech/exception-handling-in-java-part-1/图片来自:https://chercher.tech/java-programming/exceptions-java在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类 Exception(异常)和 Error(错误)。Exception 能被程序本身处理(try-catch), Error 是无法处理的(只能尽量避免)。Exception 和 Error 二者都是 Java 异常处理的重要子类,各自都包含大量子类。Exception :程序本身可以处理的异常,可以通过 catch 来进行捕获。Exception 又可以分为 受检查异常(必须处理) 和 不受检查异常(可以不处理)。Error :Error 属于程序无法处理的错误 ,我们没办法通过 catch 来进行捕获 。例如,Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。受检查异常Java 代码在编译过程中,如果受检查异常没有被 catch/throw 处理的话,就没办法通过编译 。比如下面这段 IO 操作的代码。除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有: IO 相关的异常、ClassNotFoundException 、SQLException...。不受检查异常Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。RuntimeException 及其子类都统称为非受检查异常,例如:NullPointerException、NumberFormatException(字符串转换为数字)、ArrayIndexOutOfBoundsException(数组越界)、ClassCastException(类型转换错误)、ArithmeticException(算术错误)等。Throwable 类常用方法public string getMessage():返回异常发生时的简要描述public string toString():返回异常发生时的详细信息public string getLocalizedMessage():返回异常对象的本地化信息。使用 Throwable 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 getMessage()返回的结果相同public void printStackTrace():在控制台上打印 Throwable 对象封装的异常信息try-catch-finallytry块: 用于捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。catch块: 用于处理 try 捕获到的异常。finally 块: 无论是否捕获或处理异常,finally 块里的语句都会被执行。当在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。在以下 3 种特殊情况下,finally 块不会被执行:在 try 或 finally块中用了 System.exit(int)退出程序。但是,如果 System.exit(int) 在异常语句之后,finally 还是会被执行程序所在的线程死亡。关闭 CPU。下面这部分内容来自 issue:https://github.com/Snailclimb/JavaGuide/issues/190。注意: 当 try 语句和 finally 语句中都有 return 语句时,在方法返回之前,finally 语句的内容将被执行,并且 finally 语句的返回值将会覆盖原始的返回值。如下:public class Test { public static int f(int value) { try { return value * value; } finally { if (value == 2) { return 0; } } } }如果调用 f(2),返回值将是 0,因为 finally 语句的返回值覆盖了 try 语句块的返回值。使用 try-with-resources 来代替try-catch-finally适用范围(资源的定义): 任何实现 java.lang.AutoCloseable或者 java.io.Closeable 的对象关闭资源和 finally 块的执行顺序: 在 try-with-resources 语句中,任何 catch 或 finally 块在声明的资源关闭后运行《Effecitve Java》中明确指出:面对必须要关闭的资源,我们总是应该优先使用 try-with-resources 而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。Java 中类似于InputStream、OutputStream 、Scanner 、PrintWriter等的资源都需要我们调用close()方法来手动关闭,一般情况下我们都是通过try-catch-finally语句来实现这个需求,如下: //读取文本文件的内容 Scanner scanner = null; try { scanner = new Scanner(new File("D://read.txt")); while (scanner.hasNext()) { System.out.println(scanner.nextLine()); } } catch (FileNotFoundException e) { e.printStackTrace(); } finally { if (scanner != null) { scanner.close(); } }使用 Java 7 之后的 try-with-resources 语句改造上面的代码:try (Scanner scanner = new Scanner(new File("test.txt"))) { while (scanner.hasNext()) { System.out.println(scanner.nextLine()); }} catch (FileNotFoundException fnfe) { fnfe.printStackTrace();}当然多个资源需要关闭的时候,使用 try-with-resources 实现起来也非常简单,如果你还是用try-catch-finally可能会带来很多问题。通过使用分号分隔,可以在try-with-resources块中声明多个资源。try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt"))); BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) { int b; while ((b = bin.read()) != -1) { bout.write(b); } } catch (IOException e) { e.printStackTrace(); }I/O 流什么是序列化?什么是反序列化?如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。简单来说:序列化: 将数据结构或对象转换成二进制字节流的过程反序列化:将在序列化过程中所生成的二进制字节流的过程转换成数据结构或者对象的过程对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。维基百科是如是介绍序列化的:序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。https://www.corejavaguru.com/java/serialization/interview-questions-1Java 序列化中如果有些字段不想进行序列化,怎么办?对于不想进行序列化的变量,使用transient关键字修饰。`transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。获取用键盘输入常用的两种方法方法 1:通过 ScannerScanner input = new Scanner(System.in);String s = input.nextLine();input.close();方法 2:通过 BufferedReaderBufferedReader input = new BufferedReader(new InputStreamReader(System.in));String s = input.readLine();Java 中 IO 流分为几种?按照流的流向分,可以分为输入流和输出流;按照操作单元划分,可以划分为字节流和字符流;按照流的角色划分为节点流和处理流。Java Io 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。按操作方式分类结构图:按操作对象分类结构图:既然有了字节流,为什么还要有字符流?问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。4. 参考https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jrehttps://www.educba.com/oracle-vs-openjdk/https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk 基础概念与常识
Java基础概念与常识 Java 语言有哪些特点?简单易学;面向对象(封装,继承,多态);平台无关性( Java 虚拟机实现平台无关性);支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);可靠性;安全性;支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);编译与解释并存;JVM vs JDK vs JREJVMJava 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。什么是字节码?采用字节码的好处是什么?在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。Java 程序从源代码到运行一般有下面 3 步:我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。总结:Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。JDK 和 JREJDK 是 Java Development Kit 缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装 JDK 了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何 Java 开发,仍然需要安装 JDK。例如,如果要使用 JSP 部署 Web 应用程序,那么从技术上讲,您只是在应用程序服务器中运行 Java 程序。那你为什么需要 JDK 呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。为什么说 Java 语言“编译与解释并存”?高级编程语言按照程序的执行方式分为编译型和解释型两种。简单来说,编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。比如,你想阅读一本英文名著,你可以找一个英文翻译人员帮助你阅读,有两种选择方式,你可以先等翻译人员将全本的英文名著(也就是源码)都翻译成汉语,再去阅读,也可以让翻译人员翻译一段,你在旁边阅读一段,慢慢把书读完。Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(\*.class 文件),这种字节码必须由 Java 解释器来解释执行。因此,我们可以认为 Java 语言编译与解释并存。Oracle JDK 和 OpenJDK 的对比可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么 Oracle 和 OpenJDK 之间是否存在重大差异?下面我通过收集到的一些资料,为你解答这个被很多人忽视的问题。对于 Java 7,没什么关键的地方。OpenJDK 项目主要基于 Sun 捐赠的 HotSpot 源代码。此外,OpenJDK 被选为 Java 7 的参考实现,由 Oracle 工程师维护。关于 JVM,JDK,JRE 和 OpenJDK 之间的区别,Oracle 博客帖子在 2012 年有一个更详细的答案:问:OpenJDK 存储库中的源代码与用于构建 Oracle JDK 的代码之间有什么区别?答:非常接近 - 我们的 Oracle JDK 版本构建过程基于 OpenJDK 7 构建,只添加了几个部分,例如部署代码,其中包括 Oracle 的 Java 插件和 Java WebStart 的实现,以及一些封闭的源代码派对组件,如图形光栅化器,一些开源的第三方组件,如 Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源 Oracle JDK 的所有部分,除了我们考虑商业功能的部分。总结:Oracle JDK 大概每 6 个月发一次主要版本,而 OpenJDK 版本大概每三个月发布一次。但这不是固定的,我觉得了解这个没啥用处。详情参见:https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-release-cadence 。OpenJDK 是一个参考模型并且是完全开源的,而 Oracle JDK 是 OpenJDK 的一个实现,并不是完全开源的;Oracle JDK 比 OpenJDK 更稳定。OpenJDK 和 Oracle JDK 的代码几乎相同,但 Oracle JDK 有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择 Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用 OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到 Oracle JDK 就可以解决问题;在响应性和 JVM 性能方面,Oracle JDK 与 OpenJDK 相比提供了更好的性能;Oracle JDK 不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;Oracle JDK 使用 BCL/OTN 协议获得许可,而 OpenJDK 根据 GPL v2 许可获得许可。Java 和 C++的区别?我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过 C++,也要记下来!都是面向对象的语言,都支持封装、继承和多态Java 不提供指针来直接访问内存,程序内存更加安全Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。......import java 和 javax 有什么区别?刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准 API 的一部分。所以,实际上 java 和 javax 没有区别。这都是一个名字。基本语法字符型常量和字符串常量的区别?形式 : 字符常量是单引号引起的一个字符,字符串常量是双引号引起的 0 个或若干个字符含义 : 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)占内存大小 : 字符常量只占 2 个字节; 字符串常量占若干个字节 (注意: char 在 Java 中占两个字节),字符封装类 Character 有一个成员常量 Character.SIZE 值为 16,单位是bits,该值除以 8(1byte=8bits)后就可以得到 2 个字节java 编程思想第四版:2.2.2 节注释Java 中的注释有三种:单行注释多行注释文档注释。在我们编写代码的时候,如果代码量比较少,我们自己或者团队其他成员还可以很轻易地看懂代码,但是当项目结构一旦复杂起来,我们就需要用到注释了。注释并不会执行(编译器在编译代码之前会把代码中的所有注释抹掉,字节码中不保留注释),是我们程序员写给自己看的,注释是你的代码说明书,能够帮助看代码的人快速地理清代码之间的逻辑关系。因此,在写程序的时候随手加上注释是一个非常好的习惯。《Clean Code》这本书明确指出:代码的注释不是越详细越好。实际上好的代码本身就是注释,我们要尽量规范和美化自己的代码来减少不必要的注释。若编程语言足够有表达力,就不需要注释,尽量通过代码来阐述。举个例子:去掉下面复杂的注释,只需要创建一个与注释所言同一事物的函数即可// check to see if the employee is eligible for full benefits if ((employee.flags & HOURLY_FLAG) && (employee.age > 65))应替换为if (employee.isEligibleForFullBenefits())标识符和关键字的区别是什么?在我们编写程序的时候,需要大量地为程序、类、变量、方法等取名字,于是就有了标识符,简单来说,标识符就是一个名字。但是有一些标识符,Java 语言已经赋予了其特殊的含义,只能用于特定的地方,这种特殊的标识符就是关键字。因此,关键字是被赋予特殊含义的标识符。比如,在我们的日常生活中 ,“警察局”这个名字已经被赋予了特殊的含义,所以如果你开一家店,店的名字不能叫“警察局”,“警察局”就是我们日常生活中的关键字。Java 中有哪些常见的关键字?访问控制privateprotectedpublic 类,方法和变量修饰符abstractclassextendsfinalimplementsinterfacenative newstaticstrictfpsynchronizedtransientvolatile 程序控制breakcontinuereturndowhileifelse forinstanceofswitchcasedefault 错误处理trycatchthrowthrowsfinally 包相关importpackage 基本类型booleanbytechardoublefloatintlong shortnulltruefalse 变量引用superthisvoid 保留字gotoconst 自增自减运算符在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1,Java 提供了一种特殊的运算符,用于这种表达式,叫做自增运算符(++)和自减运算符(--)。++和--运算符可以放在变量之前,也可以放在变量之后,当运算符放在变量之前时(前缀),先自增/减,再赋值;当运算符放在变量之后时(后缀),先赋值,再自增/减。例如,当 b = ++a 时,先自增(自己增加 1),再赋值(赋值给 b);当 b = a++ 时,先赋值(赋值给 b),再自增(自己增加 1)。也就是,++a 输出的是 a+1 的值,a++输出的是 a 值。用一句口诀就是:“符号在前就先加/减,符号在后就后加/减”。continue、break、和 return 的区别是什么?在循环结构中,当循环条件不满足或者循环次数达到要求时,循环会正常结束。但是,有时候可能需要在循环的过程中,当发生了某种条件之后 ,提前终止循环,这就需要用到下面几个关键词:continue :指跳出当前的这一次循环,继续下一次循环。break :指跳出整个循环体,继续执行循环下面的语句。return 用于跳出所在方法,结束该方法的运行。return 一般有两种用法:return; :直接使用 return 结束方法执行,用于没有返回值函数的方法return value; :return 一个特定值,用于有返回值函数的方法Java 泛型了解么?什么是类型擦除?介绍一下常用的通配符?Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。Java 的泛型是伪泛型,这是因为 Java 在编译期间,所有的泛型信息都会被擦掉,这也就是通常所说类型擦除 。List<Integer> list = new ArrayList<>(); list.add(12); //这里直接添加会报错 list.add("a"); Class<? extends List> clazz = list.getClass(); Method add = clazz.getDeclaredMethod("add", Object.class); //但是通过反射添加,是可以的 add.invoke(list, "kl"); System.out.println(list);泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。1.泛型类://此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型 //在实例化泛型类时,必须指定T的具体类型 public class Generic<T> { private T key; public Generic(T key) { this.key = key; } public T getKey() { return key; } }如何实例化泛型类:Generic<Integer> genericInteger = new Generic<Integer>(123456);2.泛型接口 :public interface Generator<T> { public T method(); }实现泛型接口,不指定类型:class GeneratorImpl<T> implements Generator<T>{ @Override public T method() { return null; } }实现泛型接口,指定类型:class GeneratorImpl implements Generator<String>{ @Override public String method() { return "hello"; } }3.泛型方法 :public static <E> void printArray(E[] inputArray) { for (E element : inputArray) { System.out.printf("%s ", element); } System.out.println(); }使用:// 创建不同类型数组: Integer, Double 和 Character Integer[] intArray = { 1, 2, 3 }; String[] stringArray = { "Hello", "World" }; printArray(intArray); printArray(stringArray);常用的通配符为: T,E,K,V,?? 表示不确定的 java 类型T (type) 表示具体的一个 java 类型K V (key value) 分别代表 java 键值中的 Key ValueE (element) 代表 Element==和 equals 的区别对于基本数据类型来说,==比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。equals() 作用不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。equals()方法存在于Object类中,而Object类是所有类的直接或间接父类。Object 类 equals() 方法:public boolean equals(Object obj) { return (this == obj); }equals() 方法存在两种使用情况:类没有覆盖 equals()方法 :通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是 Object类equals()方法。类覆盖了 equals()方法 :一般我们都覆盖 equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。举个例子:public class test1 { public static void main(String[] args) { String a = new String("ab"); // a 为一个引用 String b = new String("ab"); // b为另一个引用,对象的内容一样 String aa = "ab"; // 放在常量池中 String bb = "ab"; // 从常量池中查找 if (aa == bb) // true System.out.println("aa==bb"); if (a == b) // false,非同一对象 System.out.println("a==b"); if (a.equals(b)) // true System.out.println("aEQb"); if (42 == 42.0) { // true System.out.println("true"); } } }说明:String 中的 equals 方法是被重写过的,因为 Object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。String类equals()方法:public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }hashCode()与 equals()面试官可能会问你:“你重写过 hashcode 和 equals么,为什么重写 equals 时必须重写 hashCode 方法?”1)hashCode()介绍:hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。public native int hashCode();散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)2)为什么要有 hashCode?我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode?当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals() 方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head First Java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。3)为什么重写 equals 时必须重写 hashCode 方法?如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖。hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)4)为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。因为 hashCode() 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode。我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。更多关于 hashcode() 和 equals() 的内容可以查看:Java hashCode() 和 equals()的若干问题解答基本数据类型Java 中的几种基本数据类型是什么?对应的包装类型是什么?各自占用多少字节呢?Java 中有 8 种基本数据类型,分别为:6 种数字类型 :byte、short、int、long、float、double1 种字符类型:char1 种布尔型:boolean。这 8 种基本数据类型的默认值以及所占空间的大小如下:基本类型位数字节默认值int3240short1620long6480Lbyte810char162'u0000'float3240fdouble6480dboolean1 false另外,对于 boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1 位,但是实际中会考虑计算机高效存储因素。注意:Java 里使用 long 类型的数据一定要在数值后面加上 L,否则将作为整型解析。char a = 'h'char :单引号,String a = "hello" :双引号。这八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean 。包装类型不赋值就是 Null ,而基本类型有默认值且不是 Null。另外,这个问题建议还可以先从 JVM 层面来分析。基本数据类型直接存放在 Java 虚拟机栈中的局部变量表中,而包装类型属于对象类型,我们知道对象实例都存在于堆中。相比于对象类型, 基本数据类型占用的空间非常小。《深入理解 Java 虚拟机》 :局部变量表主要存放了编译期可知的基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。自动装箱与拆箱装箱:将基本类型用它们对应的引用类型包装起来;拆箱:将包装类型转换为基本数据类型;举例:Integer i = 10; //装箱 int n = i; //拆箱上面这两行代码对应的字节码为: L1 LINENUMBER 8 L1 ALOAD 0 BIPUSH 10 INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer; PUTFIELD AutoBoxTest.i : Ljava/lang/Integer; L2 LINENUMBER 9 L2 ALOAD 0 ALOAD 0 GETFIELD AutoBoxTest.i : Ljava/lang/Integer; INVOKEVIRTUAL java/lang/Integer.intValue ()I PUTFIELD AutoBoxTest.n : I RETURN从字节码中,我们发现装箱其实就是调用了 包装类的valueOf()方法,拆箱其实就是调用了 xxxValue()方法。因此,Integer i = 10 等价于 Integer i = Integer.valueOf(10)int n = i 等价于 int n = i.intValue();8 种基本类型的包装类和常量池Java 基本类型的包装类的大部分都实现了常量池技术。Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在[0,127]范围的缓存数据,Boolean 直接返回 True Or False。Integer 缓存源码:/** *此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。 */ public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); } private static class IntegerCache { static final int low = -128; static final int high; static final Integer cache[]; }Character 缓存源码:public static Character valueOf(char c) { if (c <= 127) { // must cache return CharacterCache.cache[(int)c]; } return new Character(c); } private static class CharacterCache { private CharacterCache(){} static final Character cache[] = new Character[127 + 1]; static { for (int i = 0; i < cache.length; i++) cache[i] = new Character((char)i); } }Boolean 缓存源码:public static Boolean valueOf(boolean b) { return (b ? TRUE : FALSE); }如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。Integer i1 = 33; Integer i2 = 33; System.out.println(i1 == i2);// 输出 true Float i11 = 333f; Float i22 = 333f; System.out.println(i11 == i22);// 输出 false Double i3 = 1.2; Double i4 = 1.2; System.out.println(i3 == i4);// 输出 false下面我们来看一下问题。下面的代码的输出结果是 true 还是 flase 呢?Integer i1 = 40; Integer i2 = new Integer(40); System.out.println(i1==i2);Integer i1=40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1=Integer.valueOf(40) 。因此,i1 直接使用的是常量池中的对象。而Integer i1 = new Integer(40) 会直接创建新的对象。因此,答案是 false 。你答对了吗?记住:所有整型包装类对象之间值的比较,全部使用 equals 方法比较。方法(函数)什么是方法的返回值?方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用是接收出结果,使得它可以用于其他的操作!方法有哪几种类型?1.无参数无返回值的方法// 无参数无返回值的方法(如果方法没有返回值,不能不写,必须写void,表示没有返回值) public void f1() { System.out.println("无参数无返回值的方法"); }2.有参数无返回值的方法/** * 有参数无返回值的方法 * 参数列表由零组到多组“参数类型+形参名”组合而成,多组参数之间以英文逗号(,)隔开,形参类型和形参名之间以英文空格隔开 */ public void f2(int a, String b, int c) { System.out.println(a + "-->" + b + "-->" + c); }3.有返回值无参数的方法// 有返回值无参数的方法(返回值可以是任意的类型,在函数里面必须有return关键字返回对应的类型) public int f3() { System.out.println("有返回值无参数的方法"); return 2; }4.有返回值有参数的方法// 有返回值有参数的方法 public int f4(int a, int b) { return a * b; }5.return 在无返回值方法的特殊使用// return在无返回值方法的特殊使用 public void f5(int a) { if (a > 10) { return;//表示结束所在方法 (f5方法)的执行,下方的输出语句不会执行 } System.out.println(a); }在一个静态方法内调用一个非静态成员为什么是非法的?这个需要结合 JVM 的相关知识,静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象实例化之后才存在,然后通过类的实例对象去访问。在类的非静态成员不存在的时候静态成员就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。静态方法和实例方法有何不同?在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。为什么 Java 中只有值传递?首先,我们回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。按值调用(call by value) 表示方法接收的是调用者提供的值,按引用调用(call by reference) 表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。下面通过 3 个例子来给大家说明example 1public static void main(String[] args) { int num1 = 10; int num2 = 20; swap(num1, num2); System.out.println("num1 = " + num1); System.out.println("num2 = " + num2); } public static void swap(int a, int b) { int temp = a; a = b; b = temp; System.out.println("a = " + a); System.out.println("b = " + b); }结果:a = 20 b = 10 num1 = 10 num2 = 20解析:在 swap 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 中的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.example 2 public static void main(String[] args) { int[] arr = { 1, 2, 3, 4, 5 }; System.out.println(arr[0]); change(arr); System.out.println(arr[0]); } public static void change(int[] array) { // 将数组的第一个元素变为0 array[0] = 0; }结果:1 0解析:array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的是同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。很多程序设计语言(特别是,C++和 Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为 Java 程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。example 3public class Test { public static void main(String[] args) { // TODO Auto-generated method stub Student s1 = new Student("小张"); Student s2 = new Student("小李"); Test.swap(s1, s2); System.out.println("s1:" + s1.getName()); System.out.println("s2:" + s2.getName()); } public static void swap(Student x, Student y) { Student temp = x; x = y; y = temp; System.out.println("x:" + x.getName()); System.out.println("y:" + y.getName()); } }结果:x:小李 y:小张 s1:小张 s2:小李解析:交换之前:交换之后:通过上面两张图可以很清晰的看出: 方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap 方法的参数 x 和 y 被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝总结Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按值传递的。下面再总结一下 Java 中方法参数的使用情况:一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。一个方法可以改变一个对象参数的状态。一个方法不能让对象参数引用一个新的对象。参考:《Java 核心技术卷 Ⅰ》基础知识第十版第四章 4.5 小节重载和重写的区别重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法重载发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。下面是《Java 核心技术》对重载这个概念的介绍:综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。重写重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。返回值类型、方法名、参数列表必须相同,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。如果父类方法访问修饰符为 private/final/static 则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。构造方法无法被重写综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变暖心的 Guide 哥最后再来个图表总结一下!区别点重载方法重写方法发生范围同一个类子类参数列表必须修改一定不能修改返回类型可修改子类方法返回值类型应比父类方法返回值类型更小或相等异常可修改子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;访问修饰符可修改一定不能做更严格的限制(可以降低限制)发生阶段编译期运行期方法的重写要遵循“两同两小一大”(以下内容摘录自《疯狂 Java 讲义》,issue#892 ):“两同”即方法名相同、形参列表相同;“两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;“一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。⭐️ 关于 重写的返回值类型 这里需要额外多说明一下,上面的表述不太清晰准确:如果方法的返回类型是 void 和基本数据类型,则返回值重写时不可修改。但是如果方法的返回值是引用类型,重写时是可以返回该引用类型的子类的。public class Hero { public String name() { return "超级英雄"; } } public class SuperMan extends Hero{ @Override public String name() { return "超人"; } public Hero hero() { return new Hero(); } } public class SuperSuperMan extends SuperMan { public String name() { return "超级超级英雄"; } @Override public SuperMan hero() { return new SuperMan(); } }深拷贝 vs 浅拷贝浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。Java 面向对象面向对象和面向过程的区别面向过程 :面向过程性能比面向对象高。 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix 等一般采用面向过程开发。但是,面向过程没有面向对象易维护、易复用、易扩展。面向对象 :面向对象易维护、易复用、易扩展。 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,面向对象性能比面向过程低。参见 issue : 面向过程 :面向过程性能比面向对象高??这个并不是根本原因,面向过程也需要分配内存,计算内存偏移量,Java 性能差的主要原因并不是因为它是面向对象语言,而是 Java 是半编译语言,最终的执行代码并不是可以直接被 CPU 执行的二进制机械码。而面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比 Java 好。成员变量与局部变量的区别有哪些?从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。从变量在内存中的存储方式来看,如果成员变量是使用 static 修饰的,那么这个成员变量是属于类的,如果没有使用 static 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。从变量是否有默认值来看,成员变量如果没有被赋初,则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。创建一个对象用什么运算符?对象实体与对象引用有何不同?new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向 0 个或 1 个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有 n 个引用指向它(可以用 n 条绳子系住一个气球)。对象的相等与指向他们的引用相等,两者有什么不同?对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?构造方法主要作用是完成对类对象的初始化工作。如果一个类没有声明构造方法,也可以执行!因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法了,这时候,就不能直接 new 一个对象而不传递参数了,所以我们一直在不知不觉地使用构造方法,这也是为什么我们在创建对象的时候后面要加一个括号(因为要调用无参的构造方法)。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。构造方法有哪些特点?是否可被 override?特点:名字与类名相同。没有返回值,但不能用 void 声明构造函数。生成类的对象时自动执行,无需调用。构造方法不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。面向对象三大特征封装封装是指把一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。就好像我们看不到挂在墙上的空调的内部的零件信息(也就是属性),但是可以通过遥控器(方法)来控制空调。如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。就好像如果没有空调遥控器,那么我们就无法操控空凋制冷,空调本身就没有意义了(当然现在还有很多其他方法 ,这里只是为了举例子)。public class Student { private int id;//id属性私有化 private String name;//name属性私有化 //获取id的方法 public int getId() { return id; } //设置id的方法 public void setId(int id) { this.id = id; } //获取name的方法 public String getName() { return name; } //设置name的方法 public void setName(String name) { this.name = name; } }继承不同类型的对象,相互之间经常有一定数量的共同点。例如,小明同学、小红同学、小李同学,都共享学生的特性(班级、学号等)。同时,每一个对象还定义了额外的特性使得他们与众不同。例如小明的数学比较好,小红的性格惹人喜爱;小李的力气比较大。继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承,可以快速地创建新的类,可以提高代码的重用,程序的可维护性,节省大量创建新类的时间 ,提高我们的开发效率。关于继承如下 3 点请记住:子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。子类可以拥有自己属性和方法,即子类可以对父类进行扩展。子类可以用自己的方式实现父类的方法。(以后介绍)。多态多态,顾名思义,表示一个对象具有多种的状态。具体表现为父类的引用指向子类的实例。多态的特点:对象类型和引用类型之间具有继承(类)/实现(接口)的关系;引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定;多态不能调用“只在子类存在但在父类不存在”的方法;如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?可变性简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以String 对象是不可变的。补充(来自issue 675):在 Java 9 之后,String 、StringBuilder 与 StringBuffer 的实现改用 byte 数组存储字符串 private final byte[] value而 StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是AbstractStringBuilder 实现的,大家可以自行查阅源码。AbstractStringBuilder.javaabstract class AbstractStringBuilder implements Appendable, CharSequence { /** * The value is used for character storage. */ char[] value; /** * The count is the number of characters used. */ int count; AbstractStringBuilder(int capacity) { value = new char[capacity]; }}线程安全性String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。性能每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。对于三者使用的总结:操作少量的数据: 适用 String单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder多线程操作字符串缓冲区下操作大量数据: 适用 StringBufferObject 类的常见方法总结Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。 public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。 public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。 protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。 public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。 public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。 public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。 public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。 public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。 public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念 protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作反射何为反射?如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。反射机制优缺点优点 : 可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利缺点 :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。Java Reflection: Why is it so slow?反射的应用场景像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 Method 来调用指定的方法。public class DebugInvocationHandler implements InvocationHandler { /** * 代理类中的真实对象 */ private final Object target; public DebugInvocationHandler(Object target) { this.target = target; } public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException { System.out.println("before method " + method.getName()); Object result = method.invoke(target, args); System.out.println("after method " + method.getName()); return result; } } 另外,像 Java 中的一大利器 注解 的实现也用到了反射。为什么你使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。异常Java 异常类层次结构图图片来自:https://simplesnippets.tech/exception-handling-in-java-part-1/图片来自:https://chercher.tech/java-programming/exceptions-java在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类 Exception(异常)和 Error(错误)。Exception 能被程序本身处理(try-catch), Error 是无法处理的(只能尽量避免)。Exception 和 Error 二者都是 Java 异常处理的重要子类,各自都包含大量子类。Exception :程序本身可以处理的异常,可以通过 catch 来进行捕获。Exception 又可以分为 受检查异常(必须处理) 和 不受检查异常(可以不处理)。Error :Error 属于程序无法处理的错误 ,我们没办法通过 catch 来进行捕获 。例如,Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。受检查异常Java 代码在编译过程中,如果受检查异常没有被 catch/throw 处理的话,就没办法通过编译 。比如下面这段 IO 操作的代码。除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有: IO 相关的异常、ClassNotFoundException 、SQLException...。不受检查异常Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。RuntimeException 及其子类都统称为非受检查异常,例如:NullPointerException、NumberFormatException(字符串转换为数字)、ArrayIndexOutOfBoundsException(数组越界)、ClassCastException(类型转换错误)、ArithmeticException(算术错误)等。Throwable 类常用方法public string getMessage():返回异常发生时的简要描述public string toString():返回异常发生时的详细信息public string getLocalizedMessage():返回异常对象的本地化信息。使用 Throwable 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 getMessage()返回的结果相同public void printStackTrace():在控制台上打印 Throwable 对象封装的异常信息try-catch-finallytry块: 用于捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。catch块: 用于处理 try 捕获到的异常。finally 块: 无论是否捕获或处理异常,finally 块里的语句都会被执行。当在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。在以下 3 种特殊情况下,finally 块不会被执行:在 try 或 finally块中用了 System.exit(int)退出程序。但是,如果 System.exit(int) 在异常语句之后,finally 还是会被执行程序所在的线程死亡。关闭 CPU。下面这部分内容来自 issue:https://github.com/Snailclimb/JavaGuide/issues/190。注意: 当 try 语句和 finally 语句中都有 return 语句时,在方法返回之前,finally 语句的内容将被执行,并且 finally 语句的返回值将会覆盖原始的返回值。如下:public class Test { public static int f(int value) { try { return value * value; } finally { if (value == 2) { return 0; } } } }如果调用 f(2),返回值将是 0,因为 finally 语句的返回值覆盖了 try 语句块的返回值。使用 try-with-resources 来代替try-catch-finally适用范围(资源的定义): 任何实现 java.lang.AutoCloseable或者 java.io.Closeable 的对象关闭资源和 finally 块的执行顺序: 在 try-with-resources 语句中,任何 catch 或 finally 块在声明的资源关闭后运行《Effecitve Java》中明确指出:面对必须要关闭的资源,我们总是应该优先使用 try-with-resources 而不是try-finally。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。try-with-resources语句让我们更容易编写必须要关闭的资源的代码,若采用try-finally则几乎做不到这点。Java 中类似于InputStream、OutputStream 、Scanner 、PrintWriter等的资源都需要我们调用close()方法来手动关闭,一般情况下我们都是通过try-catch-finally语句来实现这个需求,如下: //读取文本文件的内容 Scanner scanner = null; try { scanner = new Scanner(new File("D://read.txt")); while (scanner.hasNext()) { System.out.println(scanner.nextLine()); } } catch (FileNotFoundException e) { e.printStackTrace(); } finally { if (scanner != null) { scanner.close(); } }使用 Java 7 之后的 try-with-resources 语句改造上面的代码:try (Scanner scanner = new Scanner(new File("test.txt"))) { while (scanner.hasNext()) { System.out.println(scanner.nextLine()); }} catch (FileNotFoundException fnfe) { fnfe.printStackTrace();}当然多个资源需要关闭的时候,使用 try-with-resources 实现起来也非常简单,如果你还是用try-catch-finally可能会带来很多问题。通过使用分号分隔,可以在try-with-resources块中声明多个资源。try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt"))); BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) { int b; while ((b = bin.read()) != -1) { bout.write(b); } } catch (IOException e) { e.printStackTrace(); }I/O 流什么是序列化?什么是反序列化?如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。简单来说:序列化: 将数据结构或对象转换成二进制字节流的过程反序列化:将在序列化过程中所生成的二进制字节流的过程转换成数据结构或者对象的过程对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。维基百科是如是介绍序列化的:序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。https://www.corejavaguru.com/java/serialization/interview-questions-1Java 序列化中如果有些字段不想进行序列化,怎么办?对于不想进行序列化的变量,使用transient关键字修饰。`transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。获取用键盘输入常用的两种方法方法 1:通过 ScannerScanner input = new Scanner(System.in);String s = input.nextLine();input.close();方法 2:通过 BufferedReaderBufferedReader input = new BufferedReader(new InputStreamReader(System.in));String s = input.readLine();Java 中 IO 流分为几种?按照流的流向分,可以分为输入流和输出流;按照操作单元划分,可以划分为字节流和字符流;按照流的角色划分为节点流和处理流。Java Io 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。按操作方式分类结构图:按操作对象分类结构图:既然有了字节流,为什么还要有字符流?问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。4. 参考https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jrehttps://www.educba.com/oracle-vs-openjdk/https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk 基础概念与常识 -
手把手教你定位常见Java性能问题 概述性能优化一向是后端服务优化的重点,但是线上性能故障问题不是经常出现,或者受限于业务产品,根本就没办法出现性能问题,包括笔者自己遇到的性能问题也不多,所以为了提前储备知识,当出现问题的时候不会手忙脚乱,我们本篇文章来模拟下常见的几个Java性能故障,来学习怎么去分析和定位。预备知识既然是定位问题,肯定是需要借助工具,我们先了解下需要哪些工具可以帮忙定位问题。top命令 top命令使我们最常用的Linux命令之一,它可以实时的显示当前正在执行的进程的CPU使用率,内存使用率等系统信息。top -Hp pid 可以查看线程的系统资源使用情况。vmstat命令 vmstat是一个指定周期和采集次数的虚拟内存检测工具,可以统计内存,CPU,swap的使用情况,它还有一个重要的常用功能,用来观察进程的上下文切换。字段说明如下:r: 运行队列中进程数量(当数量大于CPU核数表示有阻塞的线程)b: 等待IO的进程数量swpd: 使用虚拟内存大小free: 空闲物理内存大小buff: 用作缓冲的内存大小(内存和硬盘的缓冲区)cache: 用作缓存的内存大小(CPU和内存之间的缓冲区)si: 每秒从交换区写到内存的大小,由磁盘调入内存so: 每秒写入交换区的内存大小,由内存调入磁盘bi: 每秒读取的块数bo: 每秒写入的块数in: 每秒中断数,包括时钟中断。cs: 每秒上下文切换数。us: 用户进程执行时间百分比(user time)sy: 内核系统进程执行时间百分比(system time)wa: IO等待时间百分比id: 空闲时间百分比pidstat命令pidstat 是 Sysstat 中的一个组件,也是一款功能强大的性能监测工具,top 和 vmstat 两个命令都是监测进程的内存、CPU 以及 I/O 使用情况,而 pidstat 命令可以检测到线程级别的。pidstat命令线程切换字段说明如下:UID :被监控任务的真实用户ID。TGID :线程组ID。TID:线程ID。cswch/s:主动切换上下文次数,这里是因为资源阻塞而切换线程,比如锁等待等情况。nvcswch/s:被动切换上下文次数,这里指CPU调度切换了线程。jstack命令jstack是JDK工具命令,它是一种线程堆栈分析工具,最常用的功能就是使用 jstack pid 命令查看线程的堆栈信息,也经常用来排除死锁情况。jstat 命令它可以检测Java程序运行的实时情况,包括堆内存信息和垃圾回收信息,我们常常用来查看程序垃圾回收情况。常用的命令是jstat -gc pid。信息字段说明如下:S0C:年轻代中 To Survivor 的容量(单位 KB);S1C:年轻代中 From Survivor 的容量(单位 KB);S0U:年轻代中 To Survivor 目前已使用空间(单位 KB);S1U:年轻代中 From Survivor 目前已使用空间(单位 KB);EC:年轻代中 Eden 的容量(单位 KB);EU:年轻代中 Eden 目前已使用空间(单位 KB);OC:老年代的容量(单位 KB);OU:老年代目前已使用空间(单位 KB);MC:元空间的容量(单位 KB);MU:元空间目前已使用空间(单位 KB);YGC:从应用程序启动到采样时年轻代中 gc 次数;YGCT:从应用程序启动到采样时年轻代中 gc 所用时间 (s);FGC:从应用程序启动到采样时 老年代(Full Gc)gc 次数;FGCT:从应用程序启动到采样时 老年代代(Full Gc)gc 所用时间 (s);GCT:从应用程序启动到采样时 gc 用的总时间 (s)。jmap命令jmap也是JDK工具命令,他可以查看堆内存的初始化信息以及堆内存的使用情况,还可以生成dump文件来进行详细分析。查看堆内存情况命令jmap -heap pid。mat内存工具MAT(Memory Analyzer Tool)工具是eclipse的一个插件(MAT也可以单独使用),它分析大内存的dump文件时,可以非常直观的看到各个对象在堆空间中所占用的内存大小、类实例数量、对象引用关系、利用OQL对象查询,以及可以很方便的找出对象GC Roots的相关信息。idea中也有这么一个插件,就是JProfiler。 相关阅读:《性能诊断利器 JProfiler 快速入门和最佳实践》:https://segmentfault.com/a/1190000017795841模拟环境准备基础环境jdk1.8,采用SpringBoot框架来写几个接口来触发模拟场景,首先是模拟CPU占满情况CPU占满模拟CPU占满还是比较简单,直接写一个死循环计算消耗CPU即可。 /** * 模拟CPU占满 */ @GetMapping("/cpu/loop") public void testCPULoop() throws InterruptedException { System.out.println("请求cpu死循环"); Thread.currentThread().setName("loop-thread-cpu"); int num = 0; while (true) { num++; if (num == Integer.MAX_VALUE) { System.out.println("reset"); } num = 0; } }请求接口地址测试curl localhost:8080/cpu/loop,发现CPU立马飙升到100%通过执行top -Hp 32805 查看Java线程情况执行 printf '%x' 32826 获取16进制的线程id,用于dump信息查询,结果为 803a。最后我们执行jstack 32805 |grep -A 20 803a 来查看下详细的dump信息。这里dump信息直接定位出了问题方法以及代码行,这就定位出了CPU占满的问题。内存泄露模拟内存泄漏借助了ThreadLocal对象来完成,ThreadLocal是一个线程私有变量,可以绑定到线程上,在整个线程的生命周期都会存在,但是由于ThreadLocal的特殊性,ThreadLocal是基于ThreadLocalMap实现的,ThreadLocalMap的Entry继承WeakReference,而Entry的Key是WeakReference的封装,换句话说Key就是弱引用,弱引用在下次GC之后就会被回收,如果ThreadLocal在set之后不进行后续的操作,因为GC会把Key清除掉,但是Value由于线程还在存活,所以Value一直不会被回收,最后就会发生内存泄漏。/** * 模拟内存泄漏 */ @GetMapping(value = "/memory/leak") public String leak() { System.out.println("模拟内存泄漏"); ThreadLocal<Byte[]> localVariable = new ThreadLocal<Byte[]>(); localVariable.set(new Byte[4096 * 1024]);// 为线程添加变量 return "ok"; }我们给启动加上堆内存大小限制,同时设置内存溢出的时候输出堆栈快照并输出日志。java -jar -Xms500m -Xmx500m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/tmp/heaplog.log analysis-demo-0.0.1-SNAPSHOT.jar启动成功后我们循环执行100次,for i in {1..500}; do curl localhost:8080/memory/leak;done,还没执行完毕,系统已经返回500错误了。查看系统日志出现了如下异常:java.lang.OutOfMemoryError: Java heap space我们用jstat -gc pid 命令来看看程序的GC情况。很明显,内存溢出了,堆内存经过45次 Full Gc 之后都没释放出可用内存,这说明当前堆内存中的对象都是存活的,有GC Roots引用,无法回收。那是什么原因导致内存溢出呢?是不是我只要加大内存就行了呢?如果是普通的内存溢出也许扩大内存就行了,但是如果是内存泄漏的话,扩大的内存不一会就会被占满,所以我们还需要确定是不是内存泄漏。我们之前保存了堆 Dump 文件,这个时候借助我们的MAT工具来分析下。导入工具选择Leak Suspects Report,工具直接就会给你列出问题报告。这里已经列出了可疑的4个内存泄漏问题,我们点击其中一个查看详情。这里已经指出了内存被线程占用了接近50M的内存,占用的对象就是ThreadLocal。如果想详细的通过手动去分析的话,可以点击Histogram,查看最大的对象占用是谁,然后再分析它的引用关系,即可确定是谁导致的内存溢出。上图发现占用内存最大的对象是一个Byte数组,我们看看它到底被那个GC Root引用导致没有被回收。按照上图红框操作指引,结果如下图:我们发现Byte数组是被线程对象引用的,图中也标明,Byte数组对像的GC Root是线程,所以它是不会被回收的,展开详细信息查看,我们发现最终的内存占用对象是被ThreadLocal对象占据了。这也和MAT工具自动帮我们分析的结果一致。死锁死锁会导致耗尽线程资源,占用内存,表现就是内存占用升高,CPU不一定会飙升(看场景决定),如果是直接new线程,会导致JVM内存被耗尽,报无法创建线程的错误,这也是体现了使用线程池的好处。 ExecutorService service = new ThreadPoolExecutor(4, 10, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(1024), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); /** * 模拟死锁 */ @GetMapping("/cpu/test") public String testCPU() throws InterruptedException { System.out.println("请求cpu"); Object lock1 = new Object(); Object lock2 = new Object(); service.submit(new DeadLockThread(lock1, lock2), "deadLookThread-" + new Random().nextInt()); service.submit(new DeadLockThread(lock2, lock1), "deadLookThread-" + new Random().nextInt()); return "ok"; } public class DeadLockThread implements Runnable { private Object lock1; private Object lock2; public DeadLockThread1(Object lock1, Object lock2) { this.lock1 = lock1; this.lock2 = lock2; } @Override public void run() { synchronized (lock2) { System.out.println(Thread.currentThread().getName()+"get lock2 and wait lock1"); try { TimeUnit.MILLISECONDS.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (lock1) { System.out.println(Thread.currentThread().getName()+"get lock1 and lock2 "); } } } }我们循环请求接口2000次,发现不一会系统就出现了日志错误,线程池和队列都满了,由于我选择的当队列满了就拒绝的策略,所以系统直接抛出异常。java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@2760298 rejected from java.util.concurrent.ThreadPoolExecutor@7ea7cd51[Running, pool size = 10, active threads = 10, queued tasks = 1024, completed tasks = 846]通过ps -ef|grep java命令找出 Java 进程 pid,执行jstack pid 即可出现java线程堆栈信息,这里发现了5个死锁,我们只列出其中一个,很明显线程pool-1-thread-2锁住了0x00000000f8387d88等待0x00000000f8387d98锁,线程pool-1-thread-1锁住了0x00000000f8387d98等待锁0x00000000f8387d88,这就产生了死锁。Java stack information for the threads listed above: =================================================== "pool-1-thread-2": at top.luozhou.analysisdemo.controller.DeadLockThread2.run(DeadLockThread.java:30) - waiting to lock <0x00000000f8387d98> (a java.lang.Object) - locked <0x00000000f8387d88> (a java.lang.Object) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) "pool-1-thread-1": at top.luozhou.analysisdemo.controller.DeadLockThread1.run(DeadLockThread.java:30) - waiting to lock <0x00000000f8387d88> (a java.lang.Object) - locked <0x00000000f8387d98> (a java.lang.Object) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Found 5 deadlocks.线程频繁切换上下文切换会导致将大量CPU时间浪费在寄存器、内核栈以及虚拟内存的保存和恢复上,导致系统整体性能下降。当你发现系统的性能出现明显的下降时候,需要考虑是否发生了大量的线程上下文切换。 @GetMapping(value = "/thread/swap") public String theadSwap(int num) { System.out.println("模拟线程切换"); for (int i = 0; i < num; i++) { new Thread(new ThreadSwap1(new AtomicInteger(0)),"thread-swap"+i).start(); } return "ok"; } public class ThreadSwap1 implements Runnable { private AtomicInteger integer; public ThreadSwap1(AtomicInteger integer) { this.integer = integer; } @Override public void run() { while (true) { integer.addAndGet(1); Thread.yield(); //让出CPU资源 } } }这里我创建多个线程去执行基础的原子+1操作,然后让出 CPU 资源,理论上 CPU 就会去调度别的线程,我们请求接口创建100个线程看看效果如何,curl localhost:8080/thread/swap?num=100。接口请求成功后,我们执行`vmstat 1 10,表示每1秒打印一次,打印10次,线程切换采集结果如下:procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 101 0 128000 878384 908 468684 0 0 0 0 4071 8110498 14 86 0 0 0 100 0 128000 878384 908 468684 0 0 0 0 4065 8312463 15 85 0 0 0 100 0 128000 878384 908 468684 0 0 0 0 4107 8207718 14 87 0 0 0 100 0 128000 878384 908 468684 0 0 0 0 4083 8410174 14 86 0 0 0 100 0 128000 878384 908 468684 0 0 0 0 4083 8264377 14 86 0 0 0 100 0 128000 878384 908 468688 0 0 0 108 4182 8346826 14 86 0 0 0这里我们关注4个指标,r,cs,us,sy。r=100,说明等待的进程数量是100,线程有阻塞。cs=800多万,说明每秒上下文切换了800多万次,这个数字相当大了。us=14,说明用户态占用了14%的CPU时间片去处理逻辑。sy=86,说明内核态占用了86%的CPU,这里明显就是做上下文切换工作了。我们通过top命令以及top -Hp pid查看进程和线程CPU情况,发现Java线程CPU占满了,但是线程CPU使用情况很平均,没有某一个线程把CPU吃满的情况。PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 87093 root 20 0 4194788 299056 13252 S 399.7 16.1 65:34.67 java PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 87189 root 20 0 4194788 299056 13252 R 4.7 16.1 0:41.11 java 87129 root 20 0 4194788 299056 13252 R 4.3 16.1 0:41.14 java 87130 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.51 java 87133 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.59 java 87134 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.95 java 结合上面用户态CPU只使用了14%,内核态CPU占用了86%,可以基本判断是Java程序线程上下文切换导致性能问题。我们使用pidstat命令来看看Java进程内部的线程切换数据,执行pidstat -p 87093 -w 1 10 ,采集数据如下:11:04:30 PM UID TGID TID cswch/s nvcswch/s Command11:04:30 PM 0 - 87128 0.00 16.07 |__java11:04:30 PM 0 - 87129 0.00 15.60 |__java11:04:30 PM 0 - 87130 0.00 15.54 |__java11:04:30 PM 0 - 87131 0.00 15.60 |__java11:04:30 PM 0 - 87132 0.00 15.43 |__java11:04:30 PM 0 - 87133 0.00 16.02 |__java11:04:30 PM 0 - 87134 0.00 15.66 |__java11:04:30 PM 0 - 87135 0.00 15.23 |__java11:04:30 PM 0 - 87136 0.00 15.33 |__java11:04:30 PM 0 - 87137 0.00 16.04 |__java根据上面采集的信息,我们知道Java的线程每秒切换15次左右,正常情况下,应该是个位数或者小数。结合这些信息我们可以断定Java线程开启过多,导致频繁上下文切换,从而影响了整体性能。为什么系统的上下文切换是每秒800多万,而 Java 进程中的某一个线程切换才15次左右?系统上下文切换分为三种情况:1、多任务:在多任务环境中,一个进程被切换出CPU,运行另外一个进程,这里会发生上下文切换。2、中断处理:发生中断时,硬件会切换上下文。在vmstat命令中是in3、用户和内核模式切换:当操作系统中需要在用户模式和内核模式之间进行转换时,需要进行上下文切换,比如进行系统函数调用。Linux 为每个 CPU 维护了一个就绪队列,将活跃进程按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。也就是vmstat命令中的r。那么,进程在什么时候才会被调度到 CPU 上运行呢?进程执行完终止了,它之前使用的 CPU 会释放出来,这时再从就绪队列中拿一个新的进程来运行为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片被轮流分配给各个进程。当某个进程时间片耗尽了就会被系统挂起,切换到其它等待 CPU 的进程运行。进程在系统资源不足时,要等待资源满足后才可以运行,这时进程也会被挂起,并由系统调度其它进程运行。当进程通过睡眠函数 sleep 主动挂起时,也会重新调度。当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。结合我们之前的内容分析,阻塞的就绪队列是100左右,而我们的CPU只有4核,这部分原因造成的上下文切换就可能会相当高,再加上中断次数是4000左右和系统的函数调用等,整个系统的上下文切换到800万也不足为奇了。Java内部的线程切换才15次,是因为线程使用Thread.yield()来让出CPU资源,但是CPU有可能继续调度该线程,这个时候线程之间并没有切换,这也是为什么内部的某个线程切换次数并不是非常大的原因。总结本文模拟了常见的性能问题场景,分析了如何定位CPU100%、内存泄漏、死锁、线程频繁切换问题。分析问题我们需要做好两件事,第一,掌握基本的原理,第二,借助好工具。本文也列举了分析问题的常用工具和命令,希望对你解决问题有所帮助。当然真正的线上环境可能十分复杂,并没有模拟的环境那么简单,但是原理是一样的,问题的表现也是类似的,我们重点抓住原理,活学活用,相信复杂的线上问题也可以顺利解决。参考1、https://linux.die.net/man/1/pidstat2、https://linux.die.net/man/8/vmstat3、https://help.eclipse.org/2020-03/index.jsp?topic=/org.eclipse.mat.ui.help/welcome.html4、https://www.linuxblogs.cn/articles/18120200.html5、https://www.tutorialspoint.com/what-is-context-switching-in-operating-system
-
CentOS 7 部署环境安装 JDK+Nginx+MySQL+Redis+Tomcat+Docker 安装JDK下面两种方式都可以安装,第一个是安装JRE,另一个是安装JDK。JRE 和 JDK 有什么区别?JRE(Java Runtime Environment, Java运行环境)是提供给 Java 程序运行的最小环境,换句话说,没有 JRE,JDK 程序就无法运行。JDK(Java Development Kit,Java开发工具包)是提供给 Java 程序员的开发工具包,是整个 Java 开发的核心。换句话说,没有 JDK,Java 程序员就无法使用 Java 语言编写 Java 程序。也就是说,JDK 是用于开发 Java 程序的最小环境。JVM(Java Virtual Machine, Java虚拟机)是JRE的一部分。JVM主要工作是解释自己的指令集(即字节码)并映射到本地的CPU指令集和OS的系统调用。Java语言是跨平台运行的,不同的操作系统会有不同的JVM映射规则,使之与操作系统无关,完成跨平台性。1、安装 OpenJDK 8 JREsudo yum install java-1.8.0-openjdk2、安装 OpenJDK 8 JDKsudo yum install java-1.8.0-openjdk-devel验证是否安装成功java -version // 或 javac -version查看Java路径update-alternatives --config java把 Java 添加到环境变量中编辑 .bash_profile 文件vim .bash_profile将光标移到文件最后,按 a 输入,填写路径:export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar填写完,让修改生效source .bash_profile查看修改结果:echo $JAVA_HOME // 输出结果 /usr/lib/jvm/java-1.8.0-openjdk另一种方式,下载JDK手动安装下载JDK,上传到服务器或者服务器直接下载 jdk:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html mkdir /usr/local/java/ tar -zxvf jdk-8u291-linux-x64-demos.tar.gz -C /usr/local/java/ vi /etc/profile export JAVA_HOME=/usr/local/java/jdk-8u291 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=$PATH:${JAVA_HOME}/bin source /etc/profile安装 MySQL使用yum安装mysql5.7wget http://repo.mysql.com/mysql57-community-release-el7-11.noarch.rpm # mysql8 # wget http://repo.mysql.com/mysql80-community-release-el8-1.noarch.rpm rpm -ivh mysql57-community-release-el7-11.noarch.rpm #如果直接安装可能会报错,所以这一步看需要 yum module disable mysql # 安装mysql server yum -y install mysql-community-server # 启动mysql systemctl start mysqld.service # 查看mysql状态 systemctl status mysqld.service # 查看mysql初始密码 grep "password" /var/log/mysqld.log # 登录mysql mysql -u root -p # 更改密码,有字符要求 ALTER USER 'root'@'localhost' IDENTIFIED BY '新密码'; # 开启远程连接(通常不建议,因为不安全) GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION; # 刷新权限 flush privileges;安装Nginx安装编译环境sudo yum install -y gcc-c++ sudo yum install -y pcre pcre-devel sudo yum install -y zlib zlib-devel sudo yum install -y openssl openssl-devel添加Nginx仓库sudo yum install epel-release执行安装sudo yum install nginx启动Nginxsudo systemctl start nginx设置开机自启动sudo systemctl enable nginx安装Redis安装前更新软件源yum update -y下载Redis源码wget https://download.redis.io/releases/redis-6.2.5.tar.gz安装C++编译环境# 安装c++ yum install gcc-c++ -y # 查看版本 gcc -v编译安装tar -zxvf redis-6.2.5.tar.gz cd redis-6.2.5 make # 默认安装,通常这个就够了,安装在 /usr/local/bin make install # 自定义安装,PREFIX 是你想要安装的路径 # make install PREFIX=/usr/local/redis设置开机自启动# 进入到刚开始解压的redis-6.2.5目录中,把配置文件复制到安装目录中 cp redis.conf /usr/local/bin/ cd usr/local/bin # 编辑配置文件,把 daemonized 的值从 no 改为 yes,并保存,退出 vim redis.conf cd /etc/systemd/system # 创建自启动服务空白文件 touch redis.service编辑 redis.service,写入以下代码[Unit] #服务描述 Description=Redis Server Manager #服务类别 After=syslog.target network.target [Service] #后台运行的形式 Type=forking #服务命令。 路径根据自己实际情况填写,默认安装的话是下面这个路径 ExecStart=/usr/local/bin/redis-server /usr/local/bin/redis.conf #给服务分配独立的临时空间 PrivateTmp=true [Install] #运行级别下服务安装的相关设置,可设置为多用户,即系统运行级别为3 WantedBy=multi-user.target常用命令#启动redis服务 systemctl start redis.service #设置redis开机自启动 systemctl enable redis.service #停止redis开机自启动 systemctl disable redis.service #查看redis服务当前状态 systemctl status redis.service #重新启动redis服务 systemctl restart redis.service #查看所有已启动的服务 systemctl list-units --type=service(可选)开启远程连接firewall-cmd --zone=public --add-port=6379/tcp --permanent firewall-cmd --reload修改 redis.conf 配置文件关闭 protected-mode 模式,即将其值设置成 no, 此时外部网络可以直接访问将 bind 127.0.0.1 修改成 bind * -::* 。 或者直接将bind这一行注释掉设置密码,在 protected-mode yes 下面添加一行 requirepass password使用redis-cli连接其他服务器redis进入到 /usr/local/bin 目录,执行以下代码./redis-cli -h 你服务器的ip -p 6379 -a 你的密码安装Tomcat下载Tomcat安装包官方Tomcat8下载:https://tomcat.apache.org/download-80.cgi# 进入到你想安装的目录,比如 /usr/local/tomcat wget https://downloads.apache.org/tomcat/tomcat-8/v8.5.66/bin/apache-tomcat-8.5.66.tar.gz安装tar -zxvf apache-tomcat-8.5.47.tar.gz启动进入到tomcat目录,比如上面说的目录cd /usr/local/tomcat/apache-tomcat-8.5.47/bin ./startup.sh查看是否启动成功ps -ef | grep tomcat设置Tomcat开机自启动进入到 tomcat 的 bin 目录,就是启动那一步的 bin 目录,创建一个脚本 setenv.sh# 设置Tomcat的PID文件 CATALINA_PID="$CATALINA_BASE/tomcat.pid" # 添加JVM选项 JAVA_OPTS="-server -XX:PermSize=256M -XX:MaxPermSize=1024m -Xms512M -Xmx1024M -XX:MaxNewSize=256m"在/usr/local/tomcat/apache-tomcat-8.5.47/bin/catalina.sh文件开头添加JAVA_HOME和JRE_HOME,其中 /usr/lib/jvm/java-1.8.0-openjdk 为 jdk 的安装目录export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export JRE_HOME=/usr/lib/jvm/java-1.8.0-openjdk/jre如果在catalina.sh不配置JAVA_HOME和JRE_HOME就会报错误在 /usr/lib/systemd/system 路径下添加 tomcat.service 文件,内容如下:[Unit] Description=Tomcat After=network.target remote-fs.target nss-lookup.target [Service] Type=forking TimeoutSec=0 PIDFile=/usr/local/tomcat/apache-tomcat-8.5.47/tomcat.pid ExecStart=/usr/local/tomcat/apache-tomcat-8.5.47/bin/startup.sh ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s QUIT $MAINPID PrivateTmp=true [Install] WantedBy=multi-user.targetservice 文件修改后需要调用systemctl daemon-reload命令重新加载配置TimeoutSec=0的目的是让开机启动不处理tomcat启动超时,保证tomcat耗时过长时不会被系统terminating,如果不配置可能出现错误把Tomcat加入自启动列表systemctl enable tomcat.service安装Dockeryum install -y yum-utils device-mapper-persistent-dat yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum install docker-ce
-
小米路由器 AX3600 开启SSH教程,官方固件即可安装 ShellClash开启科学上网 小米 AX3600 采用的是高通 IPQ8071A 4核心 1.4GHz A53 的 CPU,外加上双核主频高达 1.7GHz 的 NPU,这让这款路由器的跑「加密解密」类的代理性能特别特别的好。开启 SSH 和 安装 ShellClash 都不会影响固件正常的更新升级,也不会影响官方固件的功能, 如果你有这方面的需求会是非常棒的选择。你基本不需要任何准备,有台能上网的电脑甚至手机都可以,最好用网线连接到小米 AX3600 路由器。提前下载好所需文件,下载链接:隐藏内容,请前往内页查看详情开启 AX3600 SSH降级下载 AX3600 1.0.17 的固件,在路由器后台选择本地「固件升级」,就会清除现有数据降级,等待降级完成后重新设置好路由器即可。获取后台 STOK 登陆小米路由器后台后,浏览器地址栏 stok= 后面的一段内容即是(选中部分),准备好备用。获取 SSHhttp://192.168.31.1/cgi-bin/luci/;stok=<STOK>/api/misystem/set_config_iotdev?bssid=Xiaomi&user_id=longdike&ssid=-h%3B%20nvram%20set%20ssh_en%3D1%3B%20nvram%20commit%3B%20sed%20-i%20's%2Fchannel%3D.*%2Fchannel%3D%5C%22debug%5C%22%2Fg'%20%2Fetc%2Finit.d%2Fdropbear%3B%20%2Fetc%2Finit.d%2Fdropbear%20start%3B将 替换为上一步的值,替换完成后复制到浏览器打开。修改默认 SSH 密码为 adminhttp://192.168.31.1/cgi-bin/luci/;stok=<STOK>/api/misystem/set_config_iotdev?bssid=Xiaomi&user_id=longdike&ssid=-h%3B%20echo%20-e%20'admin%5Cnadmin'%20%7C%20passwd%20root%3B将 替换为上上一步的值,替换完成后复制到浏览器打开。备份现在应该可以通过 ssh 连接到 小米 AX3600 了,终端里执行(密码是 admin)ssh root@192.168.31.1在小米 AX3600 上执行mkdir /tmp/syslogbackup/ dd if=/dev/mtd9 of=/tmp/syslogbackup/mtd9浏览器请求该地址下载备份 http://192.168.31.1/backup/log/mtd9固化 SSH在电脑上将下载好的 fuckax3600 上传到小米 AX3600 的根目录(fuckax3600 路径下执行)scp fuckax3600 root@192.168.31.1:/tmp然后在小米 AX3600 上执行chmod +x /tmp/fuckax3600 /tmp/fuckax3600 unlock系统会自动重启重新 SCP 上传一遍脚本(因为 tmp 重启会被清空)scp fuckax3600 root@192.168.31.1:/tmpSSH 重新连接上小米 AX3600 后,执行chmod +x /tmp/fuckax3600 /tmp/fuckax3600 hack /tmp/fuckax3600 lock这会设置永久的 ssh、telnet、uart 权限,也会计算出默认的密码,记得保存备注:如果升级后丢失 SSH 权限,你也可以 telnet 连接上 AX3600 后执行,即可恢复 SSH。telnet 192.168.31.1 (用户名是 root,秘密是刚才得出的密码)如果你的电脑提示没有 telnet, Windows打开Telnet教程 ,Mac 则是先安装 brew 再通过 brew 安装 telnet。sed -i 's/channel=.*/channel="debug"/g' /etc/init.d/dropbear /etc/init.d/dropbear start得益于小米 AX3600 超强的 CPU + NPU 组合,跑代理速度是真不错。ShellClash 这种方案虽然没有图形化 UI 操作方便,但好在不需要刷麻烦也不稳定的 openwrt 固件,直接小米官方固件也能享受到网络「加速」的福利。
-
Spring Boot 接入支付宝实战教程 支付宝推出了新的转账接口alipay.fund.trans.uni.transfer(升级后安全性更高,功能更加强大) ,老转账接口alipay.fund.trans.toaccount.transfer将不再维护,新老接口的一个区别就是新接口采用的证书验签方式。使用新接口要将sdk版本升级到最新版本。接下来看集成步骤。1、将支付宝开放平台里下载的3个证书放在resources下面2、写支付宝支付的配置文件alipay.propertiesalipay.appId=你的应用id alipay.serverUrl=https://openapi.alipay.com/gateway.do alipay.privateKey=你的应用私钥 alipay.format=json alipay.charset=UTF-8 alipay.signType=RSA2 alipay.appCertPath=/cert/appCertPublicKey_2021001164652941.crt alipay.alipayCertPath=/cert/alipayCertPublicKey_RSA2.crt alipay.alipayRootCertPath=/cert/alipayRootCert.crt3、引入POM依赖<dependency> <groupId>com.alipay.sdk</groupId> <artifactId>alipay-sdk-java</artifactId> <version>4.10.97.ALL</version> </dependency>4、将配置信息注入AliPayBeanimport lombok.Data; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.PropertySource; import org.springframework.stereotype.Component; @Component @PropertySource("classpath:/production/alipay.properties") @ConfigurationProperties(prefix = "alipay") @Data public class AliPayBean { private String appId; private String privateKey; private String publicKey; private String serverUrl; private String domain; private String format; private String charset; private String signType; private String appCertPath; private String alipayCertPath; private String alipayRootCertPath; }5、写配置类import com.alipay.api.AlipayClient; import com.alipay.api.CertAlipayRequest; import com.alipay.api.DefaultAlipayClient; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.util.FileCopyUtils; import java.io.InputStream; @Configuration public class AliConfig { @Value("${custom.http.proxyHost}") private String proxyHost; @Value("${custom.http.proxyPort}") private int proxyPort; @Value("${spring.profiles.active}") private String activeEnv; @Autowired private AliPayBean aliPayBean; @Bean(name = {"alipayClient"}) public AlipayClient alipayClientService() throws Exception{ CertAlipayRequest certAlipayRequest = new CertAlipayRequest(); //设置网关地址 certAlipayRequest.setServerUrl(aliPayBean.getServerUrl()); //设置应用Id certAlipayRequest.setAppId(aliPayBean.getAppId()); //设置应用私钥 certAlipayRequest.setPrivateKey(aliPayBean.getPrivateKey()); //设置请求格式,固定值json certAlipayRequest.setFormat(aliPayBean.getFormat()); //设置字符集 certAlipayRequest.setCharset(aliPayBean.getCharset()); //设置签名类型 certAlipayRequest.setSignType(aliPayBean.getSignType()); //如果是生产环境或者预演环境,则使用代理模式 if ("prod".equals(activeEnv) || "stage".equals(activeEnv) || "test".equals(activeEnv)) { //设置应用公钥证书路径 certAlipayRequest.setCertContent(getCertContentByPath(aliPayBean.getAppCertPath())); //设置支付宝公钥证书路径 certAlipayRequest.setAlipayPublicCertContent(getCertContentByPath(aliPayBean.getAlipayCertPath())); //设置支付宝根证书路径 certAlipayRequest.setRootCertContent(getCertContentByPath(aliPayBean.getAlipayRootCertPath())); certAlipayRequest.setProxyHost(proxyHost); certAlipayRequest.setProxyPort(proxyPort); }else { //local String serverPath = this.getClass().getResource("/").getPath(); //设置应用公钥证书路径 certAlipayRequest.setCertPath(serverPath+aliPayBean.getAppCertPath()); //设置支付宝公钥证书路径 certAlipayRequest.setAlipayPublicCertPath(serverPath+aliPayBean.getAlipayCertPath()); //设置支付宝根证书路径 certAlipayRequest.setRootCertPath(serverPath+aliPayBean.getAlipayRootCertPath()); } return new DefaultAlipayClient(certAlipayRequest); } public String getCertContentByPath(String name){ InputStream inputStream = null; String content = null; try{ inputStream = this.getClass().getClassLoader().getResourceAsStream(name); content = new String(FileCopyUtils.copyToByteArray(inputStream)); }catch (Exception e){ e.printStackTrace(); } return content; } }6、写支付工具类import com.alipay.api.AlipayApiException; import com.alipay.api.AlipayClient; import com.alipay.api.domain.AlipayTradeAppPayModel; import com.alipay.api.domain.AlipayTradeQueryModel; import com.alipay.api.request.AlipayTradeAppPayRequest; import com.alipay.api.request.AlipayTradeQueryRequest; import com.alipay.api.response.AlipayTradeAppPayResponse; import com.alipay.api.response.AlipayTradeQueryResponse; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.stereotype.Service; /** * @description:支付宝工具类 * @Date:2020-08-26 */ @Slf4j @Service public class AliPayUtils { @Autowired @Qualifier("alipayClient") private AlipayClient alipayClient; /** * 交易查询接口 * @param request * @return * @throws Exception */ public boolean isTradeQuery(AlipayTradeQueryModel model) throws AlipayApiException { AlipayTradeQueryRequest request = new AlipayTradeQueryRequest(); request.setBizModel(model); AlipayTradeQueryResponse alipayTradeQueryResponse = alipayClient.certificateExecute(request); if(alipayTradeQueryResponse.isSuccess()){ return true; } else { return false; } } /** * app支付 * @param model * @param notifyUrl * @return * @throws AlipayApiException */ public String startAppPay(AlipayTradeAppPayModel model, String notifyUrl) throws AlipayApiException { AlipayTradeAppPayRequest aliPayRequest = new AlipayTradeAppPayRequest(); model.setProductCode("QUICK_MSECURITY_PAY"); aliPayRequest.setNotifyUrl(notifyUrl); aliPayRequest.setBizModel(model); // 这里和普通的接口调用不同,使用的是sdkExecute AlipayTradeAppPayResponse aliResponse = alipayClient.sdkExecute(aliPayRequest); return aliResponse.getBody(); } /** * 转账接口 * * @param transferParams * @return AlipayFundTransToaccountTransferResponse */ public AlipayFundTransUniTransferResponse doTransferNew(TransferParams transferParams) throws Exception { String title = (StringUtils.isNotBlank(transferParams.getRemark()) ? transferParams .getRemark() : "转账"); //转账请求入参 AlipayFundTransUniTransferRequest request = new AlipayFundTransUniTransferRequest(); //转账参数 BizContentForUniTransfer bizContent = new BizContentForUniTransfer(); bizContent.setOut_biz_no(transferParams.getOutBizNo()); bizContent.setTrans_amount(MathUtil.changeF2Y(Math.abs(Integer.parseInt(transferParams.getAmount())))); bizContent.setProduct_code("TRANS_ACCOUNT_NO_PWD"); bizContent.setBiz_scene("DIRECT_TRANSFER"); bizContent.setOrder_title(title); Participant participant = new Participant(); participant.setIdentity(transferParams.getPayeeAccount()); participant.setIdentity_type(transferParams.getPayeeType()); participant.setName((StringUtils.isNotBlank(transferParams.getPayeeRealName()) ? transferParams .getPayeeRealName() : StringUtils.EMPTY)); bizContent.setPayee_info(participant); bizContent.setRemark(title); request.setBizContent(JSON.toJSONString(bizContent)); //转账请求返回 AlipayFundTransUniTransferResponse response = null; try { response = alipayClient.certificateExecute(request); } catch (Exception e) { log.info("doTransfer exception,异常信息:{}", e.toString()); log.info("doTransfer exception,支付宝返回信息:{}", JSONObject.toJSONString(response)); } log.info("doTransfer,AlipayFundTransUniTransferResponse:{}", JSONObject.toJSONString(response)); return response; } }Tips:转账用到的类@Data public class TransferParams { /** * 应用编号 */ private Long appId; /** * 创建人id */ private Long createdBy; /** * 转账业务订单号 */ private String outBizNo; /** * 收款方识别方式 */ private String payeeType; /** * 收款方账号,可以是支付宝userId或者支付宝loginId */ private String payeeAccount; /** * 转账金额,单位分 */ private String amount; /** * 付款方名称 */ private String payerShowName; /** * 收款方名称 */ private String payeeRealName; /** * 备注 */ private String remark; /** * 支付宝转账流水号 */ private String orderId; }import lombok.Data; import java.math.BigDecimal; /** * 支付宝转账参数 */ @Data public class BizContentForUniTransfer { /** * 业务订单号 */ private String out_biz_no; /** * 订单总金额,单位为元,精确到小数点后两位, */ private BigDecimal trans_amount; /** * 业务产品码, * 单笔无密转账到支付宝账户固定为:TRANS_ACCOUNT_NO_PWD; * 单笔无密转账到银行卡固定为:TRANS_BANKCARD_NO_PWD; * 收发现金红包固定为:STD_RED_PACKET; */ private String product_code; /** * 描述特定的业务场景,可传的参数如下: * DIRECT_TRANSFER:单笔无密转账到支付宝/银行卡, B2C现金红包; * PERSONAL_COLLECTION:C2C现金红包-领红包 */ private String biz_scene; /** * 转账业务的标题,用于在支付宝用户的账单里显示 */ private String order_title; /** * 原支付宝业务单号。C2C现金红包-红包领取时,传红包支付时返回的支付宝单号; * B2C现金红包、单笔无密转账到支付宝/银行卡不需要该参数。 */ private String original_order_id; /** * 业务备注 */ private String remark; /** * 转账业务请求的扩展参数,支持传入的扩展参数如下: * 1、sub_biz_scene 子业务场景,红包业务必传,取值REDPACKET,C2C现金红包、B2C现金红包均需传入; * 2、withdraw_timeliness为转账到银行卡的预期到账时间,可选(不传入则默认为T1), * 取值T0表示预期T+0到账,取值T1表示预期T+1到账,因到账时效受银行机构处理影响,支付宝无法保证一定是T0或者T1到账; */ private String business_params; /** * 支付收款对象 */ private Participant payee_info; }@Data public class Participant { /** * 参与方的唯一标识 */ private String identity; /** * 参与方的标识类型,目前支持如下类型: * 1、ALIPAY_USER_ID 支付宝的会员ID * 2、ALIPAY_LOGON_ID:支付宝登录号,支持邮箱和手机号格式 */ private String identity_type; /** * 参与方真实姓名,如果非空,将校验收款支付宝账号姓名一致性。 * 当identity_type=ALIPAY_LOGON_ID时,本字段必填。 */ private String name; }
-
红米 AX3000 (AX6) 路由器解锁 SSH 教程 准备一台搭载了 OpenWrt 系统的无线路由器(下称路由 A)红米 AX3000 (aka. AX6)(下称路由 B)一台支持网线连接的电脑(下称电脑)完整的 shell-script/unlock-redmi-ax3000 源码( 下载源码 ){message type="warning" content="注意,阉割版的AX300,比如 RA81 是不适用的!只适用于AX6!只适用于AX6!只适用于AX6!"/}步骤1、登入路由 B 后台,检查固件版本。推荐的版本号为:MiWiFi 稳定版 1.0.18(点此下载),本教程仅保证在该版本下有效 若版本号不匹配,请先升级 / 降级固件。2、将电脑与路由 A 通过有线连接进入源码目录,假设路由 A 地址为 192.168.1.1,在电脑上执行命令:scp wireless.sh root@192.168.1.1:/root/wireless.sh然后通过 SSH 连接,执行下面的命令(按回车确认):警告: 执行本脚本会更改您的网络和无线设定,执行之前请务必备份相关数据sh /root/wireless.sh3、将电脑与路由 A 断开,转接到路由 B登入路由器后台,从浏览器地址栏中获取 STOK,其中的 xxx 即为 STOKhttp://192.168.31.1/cgi-bin/luci/;stok=xxx然后 依次 访问下面的 URL(STOK 不含尖括号):注意:这可能需要花费一点时间,并且有几率失败,请多尝试几次http://192.168.31.1/cgi-bin/luci/;stok=<STOK>/api/misystem/extendwifi_connect?ssid=MEDIATEK-ARM-IS-GREAT&password=ARE-YOU-OK如出现 connect success 则代表路由 B 已成功连接到路由 A,可以继续访问下一个 URL:http://192.168.31.1/cgi-bin/luci/;stok=<STOK>/api/xqsystem/oneclick_get_remote_token?username=xxx&password=xxx&nonce=xxx如出现下图中的内容,则代表 SSH 开启成功4、将必要文件传输至路由 B 刷新路由 B 后台界面,此时 5GHz 无线连接密码已经被自动更改为 SSH 登录密码进入源码目录,在电脑上执行下列命令:scp ax3000.sh root@192.168.31.1:/etc/ax3000.sh scp fuckax3000 root@192.168.31.1:/etc/fuckax3000然后通过 SSH 连接,执行下列命令:隐藏内容,请前往内页查看详情
-
让你的软件更优秀的方法之优化if-else 完全不必要的Else块值分配前提条件检查将If-Else转换为字典—完全避免If-Else扩展应用程序—完全避免使用If-Else1、完全不必要的else块这也许是那些初级开发人员最负罪的之一。下面的示例很好地说明了当您被认为If-Else很棒时会发生什么。只需删除else块即可简化此过程。看起来更专业吧?您会经常发现实际上根本不需要else块。像在这种情况下一样,如果满足特定条件,您想做一些事情就立即返回。2、值分配如果要基于提供的某些输入为变量分配新值,请停止If-Else废话-一种更具可读性的方法。尽管很简单,但是却很糟糕。首先,If-Else很容易在这里被开关取代。但是,我们可以通过完全删除else if和else完全简化此代码。删除else if和else,我们剩下的是清晰易读的代码。注意,我也将样式更改为快速返回而不是单返回语句-如果已经找到正确的值,继续测试一个值根本没有意义。3、前提条件检查大多数情况下,我发现如果提供了无效值,则继续执行方法是没有意义的。假设我们从以前就有了DefineGender方法,要求提供的输入值必须始终为0或1。在没有值验证的情况下执行该方法没有任何意义。因此,在允许方法继续执行之前,我们需要检查一些先决条件。应用保护子句防御性编码技术,您将检查方法的输入值,然后继续执行方法。至此,我们确保仅在值落在预期范围内时才执行主逻辑。现在,IF也已被三元代替,因为不再需要在结尾处默认返回“未知”。4、将If-Else转换为字典—完全避免If-Else假设您需要执行一些操作,这些操作将根据某些条件进行选择,我们知道稍后我们将不得不添加更多操作。也许有人会倾向于使用久经考验的If-Else。如果要添加一个新的操作,只是简单地增加了一个额外的问题。很简单 但是,就维护而言,此方法不是一个很好的设计。知道我们以后需要添加新的操作后,我们可以将If-Else重构为字典。可读性已大大提高,并且可以更轻松地推断出此代码。注意,仅出于说明目的将字典放置在方法内部。您可能希望从其他地方提供它。5、扩展应用程序—完全避免使用If-Else这是一个稍微高级的例子。让我也快速澄清一些实际问题……这是一种更“主动”的方法。这不会是您典型的“让我只用if-else代替”的情况。现在,继续阅读。通过用对象替换,知道何时甚至完全消除If。通常,您会发现自己不得不扩展应用程序的某些部分。作为初级开发人员,您可能倾向于通过添加一个额外的If-Else(即else-if)语句来做到这一点。以这个典型的例子为例。在这里,我们需要将Order实例显示为字符串。首先,我们只有两种字符串表示形式:JSON和纯文本。使用的if-else在这个阶段是不是一个大问题,寿,我们可以很容易地更换else if只需if正如前面证明。知道我们需要扩展应用程序的这一部分,这种方法绝对是不可接受的。上面的代码不仅违反了Open / Closed原理,而且阅读效果也不佳,并且会引起可维护性方面的麻烦。正确的方法是遵循SOLID原则的方法-我们通过实施动态类型发现过程(在本例中为策略模式)来做到这一点。重构此混乱热点的过程如下:使用公共接口将每个分支提取到单独的策略类中动态查找实现公共接口的所有类根据输入决定执行哪种策略将替换上面示例的代码如下所示。是的,这是更多代码的方式。它要求您了解类型发现的工作原理。但是动态扩展应用程序是一个高级主题。我只显示将替换If-Else示例的确切部分。如果要查看所有涉及的对象,请查看此要点。理想情况下,类型发现和字典将发生在PrintOrder方法之外。但是无论如何,让我们快速浏览一下代码。方法签名保持不变,因为调用者不需要了解我们的重构。首先,获取实现通用接口的程序集中的所有类型IOrderOutputStrategy。然后,我们建立一个字典,格式化程序的displayName的名称为key,类型为value。然后从字典中选择格式化程序类型,然后尝试实例化策略对象。最后,ConvertOrderToString调用策略对象。
-