搜索到
11
篇与
的结果
-
 1.8w 字详解 SQL 优化 分享一篇关于SQL优化的硬核文章,全文有点长,建议收藏后慢慢看。很多朋友在做数据分析时,分析两分钟,跑数两小时?在使用SQL过程中不仅要关注数据结果,同样要注意SQL语句的执行效率。本文涉及三部分:SQL介绍SQL优化方法SQL优化实例1、MySQL的基本架构1)MySQL的基础架构图左边的client可以看成是客户端,客户端有很多,像我们经常你使用的CMD黑窗口,像我们经常用于学习的WorkBench,像企业经常使用的Navicat工具,它们都是一个客户端。右边的这一大堆都可以看成是Server(MySQL的服务端),我们将Server在细分为sql层和存储引擎层。当查询出数据以后,会返回给执行器。执行器一方面将结果写到查询缓存里面,当你下次再次查询的时候,就可以直接从查询缓存中获取到数据了。另一方面,直接将结果响应回客户端。2)查询数据库的引擎① show engines;② show variables like “%storage_engine%”;3)指定数据库对象的存储引擎create table tb( id int(4) auto_increment, name varchar(5), dept varchar(5), primary key(id) ) engine=myISAM auto_increment=1 default charset=utf8;SQL优化1)为什么需要进行SQL优化?在进行多表连接查询、子查询等操作的时候,由于你写出的SQL语句欠佳,导致的服务器执行时间太长,我们等待结果的时间太长。基于此,我们需要学习怎么优化SQL。2)mysql的编写过程和解析过程① 编写过程select dinstinct ..from ..join ..on ..where ..group by ..having ..order by ..limit ..② 解析过程from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..提供一个网站,详细说明了mysql解析过程:https://www.cnblogs.com/annsshadow/p/5037667.html3)SQL优化—主要就是优化索引优化SQL,最重要的就是优化SQL索引。索引相当于字典的目录。利用字典目录查找汉字的过程,就相当于利用SQL索引查找某条记录的过程。有了索引,就可以很方便快捷的定位某条记录。① 什么是索引?索引就是帮助MySQL高效获取数据的一种【数据结构】。索引是一种树结构,MySQL中一般用的是【B+树】。② 索引图示说明(这里用二叉树来帮助我们理解索引)树形结构的特点是:子元素比父元素小的,放在左侧;子元素比父元素大的,放在右侧。这个图示只是为了帮我们简单理解索引的,真实的关于【B+树】的说明,我们会在下面进行说明。索引是怎么查找数据的呢?两个字【指向】,上图中我们给age列指定了一个索引,即类似于右侧的这种树形结构。mysql表中的每一行记录都有一个硬件地址,例如索引中的age=50,指向的就是源表中该行的标识符(“硬件地址”)。也就是说,树形索引建立了与源表中每行记录硬件地址的映射关系,当你指定了某个索引,这种映射关系也就建成了,这就是为什么我们可以通过索引快速定位源表中记录的原因。以【select * from student where age=33】查询语句为例。当我们不加索引的时候,会从上到下扫描源表,当扫描到第5行的时候,找到了我们想要找到了元素,一共是查询了5次。当添加了索引以后,就直接在树形结构中进行查找,33比50小,就从左侧查询到了23,33大于23,就又查询到了右侧,这下找到了33,整个索引结束,一共进行了3次查找。是不是很方便,假如我们此时需要查找age=62,你再想想“添加索引”前后,查找次数的变化情况。4)索引的弊端1.当数据量很大的时候,索引也会很大(当然相比于源表来说,还是相当小的),也需要存放在内存/硬盘中(通常存放在硬盘中),占据一定的内存空间/物理空间。2.索引并不适用于所有情况:a.少量数据;b.频繁进行改动的字段,不适合做索引;c.很少使用的字段,不需要加索引;3.索引会提高数据查询效率,但是会降低“增、删、改”的效率。当不使用索引的时候,我们进行数据的增删改,只需要操作源表即可,但是当我们添加索引后,不仅需要修改源表,也需要再次修改索引,很麻烦。尽管是这样,添加索引还是很划算的,因为我们大多数使用的就是查询,“查询”对于程序的性能影响是很大的。5)索引的优势1.提高查询效率(降低了IO使用率)。当创建了索引后,查询次数减少了。2.降低CPU使用率。比如说【…order by age desc】这样一个操作,当不加索引,会把源表加载到内存中做一个排序操作,极大的消耗了资源。但是使用了索引以后,第一索引本身就小一些,第二索引本身就是排好序的,左边数据最小,右边数据最大。6)B+树图示说明MySQL中索引使用的就是B+树结构。关于B+树的说明:首先,Btree一般指的都是【B+树】,数据全部存放在叶子节点中。对于上图来说,最下面的第3层,属于叶子节点,真实数据部份都是存放在叶子节点当中的。那么对于第1、2层中的数据又是干嘛的呢?答:用于分割指针块儿的,比如说小于26的找P1,介于26-30之间的找P2,大于30的找P3。其次,三层【B+树】可以存放上百万条数据。这么多数据怎么放的呢?增加“节点数”。图中我们只有三个节点。最后,【B+树】中查询任意数据的次数,都是n次,n表示的是【B+树】的高度。3、索引的分类与创建1)索引分类单值索引唯一索引复合索引① 单值索引利用表中的某一个字段创建单值索引。一张表中往往有多个字段,也就是说每一列其实都可以创建一个索引,这个根据我们实际需求来进行创建。还需要注意的一点就是,一张表可以创建多个“单值索引”。假如某一张表既有age字段,又有name字段,我们可以分别对age、name创建一个单值索引,这样一张表就有了两个单值索引。② 唯一索引也是利用表中的某一个字段创建单值索引,与单值索引不同的是:创建唯一索引的字段中的数据,不能有重复值。像age肯定有很多人的年龄相同,像name肯定有些人是重名的,因此都不适合创建“唯一索引”。像编号id、学号sid,对于每个人都不一样,因此可以用于创建唯一索引。③ 复合索引多个列共同构成的索引。比如说我们创建这样一个“复合索引”(name,age),先利用name进行索引查询,当name相同的时候,我们利用age再进行一次筛选。注意:复合索引的字段并不是非要都用完,当我们利用name字段索引出我们想要的结果以后,就不需要再使用age进行再次筛选了。2)创建索引① 语法语法:create 索引类型 索引名 on 表(字段);建表语句如下:查询表结构如下:② 创建索引的第一种方式Ⅰ 创建单值索引create index dept_index on tb(dept);Ⅱ 创建唯一索引:这里我们假定name字段中的值都是唯一的create unique index name_index on tb(name);Ⅲ 创建复合索引create index dept_name_index on tb(dept,name);③ 创建索引的第二种方式先删除之前创建的索引以后,再进行这种创建索引方式的测试;语法:alter table 表名 add 索引类型 索引名(字段)Ⅰ 创建单值索引alter table tb add index dept_index(dept);Ⅱ 创建唯一索引:这里我们假定name字段中的值都是唯一的alter table tb add unique index name_index(name);Ⅲ 创建复合索引alter table tb add index dept_name_index(dept,name);④ 补充说明如果某个字段是primary key,那么该字段默认就是主键索引。主键索引和唯一索引非常相似。相同点:该列中的数据都不能有相同值;不同点:主键索引不能有null值,但是唯一索引可以有null值。3)索引删除和索引查询① 索引删除语法:drop index 索引名 on 表名;drop index name_index on tb;② 索引查询语法:show index from 表名;show index from tb;结果如下:4、SQL性能问题的探索人为优化: 需要我们使用explain分析SQL的执行计划。该执行计划可以模拟SQL优化器执行SQL语句,可以帮助我们了解到自己编写SQL的好坏。SQL优化器自动优化: 最开始讲述MySQL执行原理的时候,我们已经知道MySQL有一个优化器,当你写了一个SQL语句的时候,SQL优化器如果认为你写的SQL语句不够好,就会自动写一个好一些的等价SQL去执行。SQL优化器自动优化功能【会干扰】我们的人为优化功能。当我们查看了SQL执行计划以后,如果写的不好,我们会去优化自己的SQL。当我们以为自己优化的很好的时候,最终的执行计划,并不是按照我们优化好的SQL语句来执行的,而是有时候将我们优化好的SQL改变了,去执行。SQL优化是一种概率问题,有时候系统会按照我们优化好的SQL去执行结果(优化器觉得你写的差不多,就不会动你的SQL)。有时候优化器仍然会修改我们优化好的SQL,然后再去执行。1)查看执行计划语法:explain + SQL语句eg:explain select * from tb;2)“执行计划”中需要知道的几个“关键字”id :编号select_type :查询类型table :表type :类型possible_keys :预测用到的索引key :实际使用的索引key_len :实际使用索引的长度ref :表之间的引用rows :通过索引查询到的数据量Extra :额外的信息建表语句和插入数据:# 建表语句 create table course ( cid int(3), cname varchar(20), tid int(3) ); create table teacher ( tid int(3), tname varchar(20), tcid int(3) ); create table teacherCard ( tcid int(3), tcdesc varchar(200) ); # 插入数据 insert into course values(1,'java',1); insert into course values(2,'html',1); insert into course values(3,'sql',2); insert into course values(4,'web',3); insert into teacher values(1,'tz',1); insert into teacher values(2,'tw',2); insert into teacher values(3,'tl',3); insert into teacherCard values(1,'tzdesc') ; insert into teacherCard values(2,'twdesc') ; insert into teacherCard values(3,'tldesc') ;explain执行计划常用关键字详解1)id关键字的使用说明① 案例:查询课程编号为2 或 教师证编号为3 的老师信息:# 查看执行计划 explain select t.* from teacher t,course c,teacherCard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3);结果如下:接着,在往teacher表中增加几条数据。insert into teacher values(4,'ta',4); insert into teacher values(5,'tb',5); insert into teacher values(6,'tc',6);再次查看执行计划。# 查看执行计划 explain select t.* from teacher t,course c,teacherCard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3);结果如下:表的执行顺序 ,因表数量改变而改变的原因:笛卡尔积。a b c 2 3 4 最终:2 * 3 * 4 = 6 * 4 = 24 c b a 4 3 2 最终:4 * 3 * 2 = 12 * 2 = 24分析:最终执行的条数,虽然是一致的。但是中间过程,有一张临时表是6,一张临时表是12,很明显6 < 12,对于内存来说,数据量越小越好,因此优化器肯定会选择第一种执行顺序。结论:id值相同,从上往下顺序执行。表的执行顺序因表数量的改变而改变。② 案例:查询教授SQL课程的老师的描述(desc)# 查看执行计划 explain select tc.tcdesc from teacherCard tc where tc.tcid = ( select t.tcid from teacher t where t.tid = (select c.tid from course c where c.cname = 'sql') );结果如下:结论:id值不同,id值越大越优先查询。这是由于在进行嵌套子查询时,先查内层,再查外层。③ 针对②做一个简单的修改# 查看执行计划 explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid and t.tid = (select c.tid from course c where cname = 'sql') ;结果如下:结论:id值有相同,又有不同。id值越大越优先;id值相同,从上往下顺序执行。2)select_type关键字的使用说明:查询类型① simple:简单查询不包含子查询,不包含union查询。explain select * from teacher;结果如下:② primary:包含子查询的主查询(最外层)③ subquery:包含子查询的主查询(非最外层)④ derived:衍生查询(用到了临时表)a.在from子查询中,只有一张表;b.在from子查询中,如果table1 union table2,则table1就是derived表;explain select cr.cname from ( select * from course where tid = 1 union select * from course where tid = 2 ) cr ;结果如下:⑤ union:union之后的表称之为union表,如上例⑥ union result:告诉我们,哪些表之间使用了union查询3)type关键字的使用说明:索引类型system、const只是理想状况,实际上只能优化到index --> range --> ref这个级别。要对type进行优化的前提是,你得创建索引。① system源表只有一条数据(实际中,基本不可能);衍生表只有一条数据的主查询(偶尔可以达到)。② const仅仅能查到一条数据的SQL ,仅针对Primary key或unique索引类型有效。explain select tid from test01 where tid =1 ;结果如下:删除以前的主键索引后,此时我们添加一个其他的普通索引:create index test01_index on test01(tid) ; # 再次查看执行计划 explain select tid from test01 where tid =1 ;结果如下:③ eq_ref唯一性索引,对于每个索引键的查询,返回匹配唯一行数据(有且只有1个,不能多 、不能0),并且查询结果和数据条数必须一致。此种情况常见于唯一索引和主键索引。delete from teacher where tcid >= 4; alter table teacherCard add constraint pk_tcid primary key(tcid); alter table teacher add constraint uk_tcid unique index(tcid) ; explain select t.tcid from teacher t,teacherCard tc where t.tcid = tc.tcid ;结果如下:总结:以上SQL,用到的索引是t.tcid,即teacher表中的tcid字段;如果teacher表的数据个数和连接查询的数据个数一致(都是3条数据),则有可能满足eq_ref级别;否则无法满足。条件很苛刻,很难达到。④ ref非唯一性索引,对于每个索引键的查询,返回匹配的所有行(可以0,可以1,可以多)准备数据:创建索引,并查看执行计划:# 添加索引 alter table teacher add index index_name (tname) ; # 查看执行计划 explain select * from teacher where tname = 'tz';结果如下:⑤ range检索指定范围的行 ,where后面是一个范围查询(between, >, <, >=, in)in有时候会失效,从而转为无索引时候的ALL# 添加索引 alter table teacher add index tid_index (tid) ; # 查看执行计划:以下写了一种等价SQL写法,查看执行计划 explain select t.* from teacher t where t.tid in (1,2) ; explain select t.* from teacher t where t.tid <3 ;结果如下:⑥ index查询全部索引中的数据(扫描整个索引)⑦ ALL查询全部源表中的数据(暴力扫描全表)注意:cid是索引字段,因此查询索引字段,只需要扫描索引表即可。但是tid不是索引字段,查询非索引字段,需要暴力扫描整个源表,会消耗更多的资源。4)possible_keys和keypossible_keys可能用到的索引。是一种预测,不准。了解一下就好。key指的是实际使用的索引。# 先给course表的cname字段,添加一个索引 create index cname_index on course(cname); # 查看执行计划 explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid and t.tid = (select c.tid from course c where cname = 'sql') ;结果如下:有一点需要注意的是:如果possible_key/key是NULL,则说明没用索引。5)key_len索引的长度,用于判断复合索引是否被完全使用(a,b,c)。① 新建一张新表,用于测试# 创建表 create table test_kl ( name char(20) not null default '' ); # 添加索引 alter table test_kl add index index_name(name) ; # 查看执行计划 explain select * from test_kl where name ='' ; 结果如下:结果分析:因为我没有设置服务端的字符集,因此默认的字符集使用的是latin1,对于latin1一个字符代表一个字节,因此这列的key_len的长度是20,表示使用了name这个索引。② 给test_kl表,新增name1列,该列没有设置“not null”结果如下:结果分析:如果索引字段可以为null,则mysql底层会使用1个字节用于标识。③ 删除原来的索引name和name1,新增一个复合索引# 删除原来的索引name和name1 drop index index_name on test_kl ; drop index index_name1 on test_kl ; # 增加一个复合索引 create index name_name1_index on test_kl(name,name1); # 查看执行计划 explain select * from test_kl where name1 = '' ; --121 explain select * from test_kl where name = '' ; --60结果如下:结果分析: 对于下面这个执行计划,可以看到我们只使用了复合索引的第一个索引字段name,因此key_len是20,这个很清楚。再看上面这个执行计划,我们虽然仅仅在where后面使用了复合索引字段中的name1字段,但是你要使用复合索引的第2个索引字段,会默认使用了复合索引的第1个索引字段name,由于name1可以是null,因此key_len = 20 + 20 + 1 = 41呀!④ 再次怎加一个name2字段,并为该字段创建一个索引。不同的是:该字段数据类型是varchar# 新增一个字段name2,name2可以为null alter table test_kl add column name2 varchar(20) ; # 给name2字段,设置为索引字段 alter table test_kl add index name2_index(name2) ; # 查看执行计划 explain select * from test_kl where name2 = '' ; 结果如下:结果分析: key_len = 20 + 1 + 2,这个20 + 1我们知道,这个2又代表什么呢?原来varchar属于可变长度,在mysql底层中,用2个字节标识可变长度。6)ref这里的ref的作用,指明当前表所参照的字段。注意与type中的ref值区分。在type中,ref只是type类型的一种选项值。# 给course表的tid字段,添加一个索引 create index tid_index on course(tid); # 查看执行计划 explain select * from course c,teacher t where c.tid = t.tid and t.tname = 'tw';结果如下:结果分析: 有两个索引,c表的c.tid引用的是t表的tid字段,因此可以看到显示结果为【数据库名.t.tid】,t表的t.name引用的是一个常量"tw",因此可以看到结果显示为const,表示一个常量。7)rows(这个目前还是有点疑惑)被索引优化查询的数据个数 (实际通过索引而查询到的数据个数)explain select * from course c,teacher t where c.tid = t.tid and t.tname = 'tz' ;结果如下:8)extra表示其他的一些说明,也很有用。① using filesort:针对单索引的情况当出现了这个词,表示你当前的SQL性能消耗较大。表示进行了一次“额外”的排序。常见于order by语句中。Ⅰ 什么是“额外”的排序?为了讲清楚这个,我们首先要知道什么是排序。我们为了给某一个字段进行排序的时候,首先你得先查询到这个字段,然后在将这个字段进行排序。紧接着,我们查看如下两个SQL语句的执行计划。# 新建一张表,建表同时创建索引 create table test02 ( a1 char(3), a2 char(3), a3 char(3), index idx_a1(a1), index idx_a2(a2), index idx_a3(a3) ); # 查看执行计划 explain select * from test02 where a1 ='' order by a1 ; explain select * from test02 where a1 ='' order by a2 ; 结果如下:结果分析: 对于第一个执行计划,where后面我们先查询了a1字段,然后再利用a1做了依次排序,这个很轻松。但是对于第二个执行计划,where后面我们查询了a1字段,然而利用的却是a2字段进行排序,此时myql底层会进行一次查询,进行“额外”的排序。总结:对于单索引,如果排序和查找是同一个字段,则不会出现using filesort;如果排序和查找不是同一个字段,则会出现using filesort;因此where哪些字段,就order by哪些些字段。② using filesort:针对复合索引的情况不能跨列(官方术语:最佳左前缀)# 删除test02的索引 drop index idx_a1 on test02; drop index idx_a2 on test02; drop index idx_a3 on test02; # 创建一个复合索引 alter table test02 add index idx_a1_a2_a3 (a1,a2,a3) ; # 查看下面SQL语句的执行计划 explain select *from test02 where a1='' order by a3 ; --using filesort explain select *from test02 where a2='' order by a3 ; --using filesort explain select *from test02 where a1='' order by a2 ;结果如下:结果分析: 复合索引的顺序是(a1,a2,a3),可以看到a1在最左边,因此a1就叫做“最佳左前缀”,如果要使用后面的索引字段,必须先使用到这个a1字段。对于explain1,where后面我们使用a1字段,但是后面的排序使用了a3,直接跳过了a2,属于跨列;对于explain2,where后面我们使用了a2字段,直接跳过了a1字段,也属于跨列;对于explain3,where后面我们使用a1字段,后面使用的是a2字段,因此没有出现【using filesort】。③ using temporary当出现了这个词,也表示你当前的SQL性能消耗较大。这是由于当前SQL用到了临时表。一般出现在group by中。explain select a1 from test02 where a1 in ('1','2','3') group by a1 ; explain select a1 from test02 where a1 in ('1','2','3') group by a2 ; --using temporary结果如下:结果分析: 当你查询哪个字段,就按照那个字段分组,否则就会出现using temporary。针对using temporary,我们在看一个例子:using temporary表示需要额外再使用一张表,一般出现在group by语句中。虽然已经有表了,但是不适用,必须再来一张表。再次来看mysql的编写过程和解析过程。Ⅰ 编写过程select dinstinct ..from ..join ..on ..where ..group by ..having ..order by ..limit ..Ⅱ 解析过程from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..很显然,where后是group by,然后才是select。基于此,我们再查看如下两个SQL语句的执行计划。explain select * from test03 where a2=2 and a4=4 group by a2,a4; explain select * from test03 where a2=2 and a4=4 group by a3;分析如下: 对于第一个执行计划,where后面是a2和a4,接着我们按照a2和a4分组,很明显这两张表已经有了,直接在a2和a4上分组就行了。但是对于第二个执行计划,where后面是a2和a4,接着我们却按照a3分组,很明显我们没有a3这张表,因此有需要再来一张临时表a3。因此就会出现using temporary。④ using index当你看到这个关键词,恭喜你,表示你的SQL性能提升了。using index称之为“索引覆盖”。当出现了using index,就表示不用读取源表,而只利用索引获取数据,不需要回源表查询。只要使用到的列,全部出现在索引中,就是索引覆盖。# 删除test02中的复合索引idx_a1_a2_a3 drop index idx_a1_a2_a3 on test02; # 重新创建一个复合索引 idx_a1_a2create index idx_a1_a2 on test02(a1,a2); # 查看执行计划 explain select a1,a3 from test02 where a1='' or a3= '' ; explain select a1,a2 from test02 where a1='' and a2= '' ;结果如下:结果分析: 我们创建的是a1和a2的复合索引,对于第一个执行计划,我们却出现了a3,该字段并没有创建索引,因此没有出现using index,而是using where,表示我们需要回表查询。对于第二个执行计划,属于完全的索引覆盖,因此出现了using index。针对using index,我们在查看一个案例:explain select a1,a2 from test02 where a1='' or a2= '' ; explain select a1,a2 from test02;结果如下:如果用到了索引覆盖(using index时),会对possible_keys和key造成影响:a.如果没有where,则索引只出现在key中;b.如果有where,则索引 出现在key和possible_keys中。⑤ using where表示需要【回表查询】,表示既在索引中进行了查询,又回到了源表进行了查询。# 删除test02中的复合索引idx_a1_a2 drop index idx_a1_a2 on test02; # 将a1字段,新增为一个索引 create index a1_index on test02(a1); # 查看执行计划 explain select a1,a3 from test02 where a1="" and a3="" ;结果如下:结果分析: 我们既使用了索引a1,表示我们使用了索引进行查询。但是又对于a3字段,我们并没有使用索引,因此对于a3字段,需要回源表查询,这个时候出现了using where。⑥ impossible where(了解)当where子句永远为False的时候,会出现impossible where# 查看执行计划 explain select a1 from test02 where a1="a" and a1="b" ;结果如下:6、优化示例1)引入案例# 创建新表 create table test03 ( a1 int(4) not null, a2 int(4) not null, a3 int(4) not null, a4 int(4) not null ); # 创建一个复合索引 create index a1_a2_a3_test03 on test03(a1,a2,a3); # 查看执行计划 explain select a3 from test03 where a1=1 and a2=2 and a3=3;结果如下:推荐写法: 复合索引顺序和使用顺序一致。下面看看【不推荐写法】:复合索引顺序和使用顺序不一致。# 查看执行计划 explain select a3 from test03 where a3=1 and a2=2 and a1=3;结果如下:结果分析: 虽然结果和上述结果一致,但是不推荐这样写。但是这样写怎么又没有问题呢?这是由于SQL优化器的功劳,它帮我们调整了顺序。最后再补充一点:对于复合索引,不要跨列使用# 查看执行计划 explain select a3 from test03 where a1=1 and a3=2 group by a3;结果如下:结果分析: a1_a2_a3是一个复合索引,我们使用a1索引后,直接跨列使用了a3,直接跳过索引a2,因此索引a3失效了,当使用a3进行分组的时候,就会出现using where。2)单表优化# 创建新表 create table book ( bid int(4) primary key, name varchar(20) not null, authorid int(4) not null, publicid int(4) not null, typeid int(4) not null ); # 插入数据 insert into book values(1,'tjava',1,1,2) ; insert into book values(2,'tc',2,1,2) ; insert into book values(3,'wx',3,2,1) ; insert into book values(4,'math',4,2,3) ; 结果如下:案例:查询authorid=1且typeid为2或3的bid,并根据typeid降序排列。explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ; 结果如下:这是没有进行任何优化的SQL,可以看到typ为ALL类型,extra为using filesort,可以想象这个SQL有多恐怖。优化:添加索引的时候,要根据MySQL解析顺序添加索引,又回到了MySQL的解析顺序,下面我们再来看看MySQL的解析顺序。from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..① 优化1:基于此,我们进行索引的添加,并再次查看执行计划。# 添加索引 create index typeid_authorid_bid on book(typeid,authorid,bid); # 再次查看执行计划 explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ;结果如下:结果分析: 结果并不是和我们想象的一样,还是出现了using where,查看索引长度key_len=8,表示我们只使用了2个索引,有一个索引失效了。② 优化2:使用了in有时候会导致索引失效,基于此有了如下一种优化思路。将in字段放在最后面。需要注意一点:每次创建新的索引的时候,最好是删除以前的废弃索引,否则有时候会产生干扰(索引之间)。# 删除以前的索引 drop index typeid_authorid_bid on book; # 再次创建索引 create index authorid_typeid_bid on book(authorid,typeid,bid); # 再次查看执行计划 explain select bid from book where authorid=1 and typeid in(2,3) order by typeid desc ;结果如下:结果分析: 这里虽然没有变化,但是这是一种优化思路。总结如下:a.最佳做前缀,保持索引的定义和使用的顺序一致性b.索引需要逐步优化(每次创建新索引,根据情况需要删除以前的废弃索引)c.将含In的范围查询,放到where条件的最后,防止失效。本例中同时出现了Using where(需要回原表); Using index(不需要回原表):原因,where authorid=1 and typeid in(2,3)中authorid在索引(authorid,typeid,bid)中,因此不需要回原表(直接在索引表中能查到);而typeid虽然也在索引(authorid,typeid,bid)中,但是含in的范围查询已经使该typeid索引失效,因此相当于没有typeid这个索引,所以需要回原表(using where);例如以下没有了In,则不会出现using where:explain select bid from book where authorid=1 and typeid =3 order by typeid desc ;结果如下:3)两表优化# 创建teacher2新表 create table teacher2 ( tid int(4) primary key, cid int(4) not null ); # 插入数据 insert into teacher2 values(1,2); insert into teacher2 values(2,1); insert into teacher2 values(3,3); # 创建course2新表 create table course2 ( cid int(4) , cname varchar(20) ); # 插入数据 insert into course2 values(1,'java'); insert into course2 values(2,'python'); insert into course2 values(3,'kotlin');案例:使用一个左连接,查找教java课程的所有信息。explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';结果如下:① 优化对于两张表,索引往哪里加?答:对于表连接,小表驱动大表。索引建立在经常使用的字段上。为什么小表驱动大表好一些呢? 小表:10 大表:300 # 小表驱动大表 select ...where 小表.x10=大表.x300 ; for(int i=0;i<小表.length10;i++) { for(int j=0;j<大表.length300;j++) { ... } } # 大表驱动小表 select ...where 大表.x300=小表.x10 ; for(int i=0;i<大表.length300;i++) { for(int j=0;j<小表.length10;j++) { ... } }分析: 以上2个FOR循环,最终都会循环3000次;但是对于双层循环来说:一般建议,将数据小的循环,放外层。数据大的循环,放内层。不用管这是为什么,这是编程语言的一个原则,对于双重循环,外层循环少,内存循环大,程序的性能越高。结论:当编写【…on t.cid=c.cid】时,将数据量小的表放左边(假设此时t表数据量小,c表数据量大。)我们已经知道了,对于两表连接,需要利用小表驱动大表,例如【…on t.cid=c.cid】,t如果是小表(10条),c如果是大表(300条),那么t每循环1次,就需要循环300次,即t表的t.cid字段属于,经常使用的字段,因此需要给cid字段添加索引。更深入的说明: 一般情况下,左连接给左表加索引。右连接给右表加索引。其他表需不需要加索引,我们逐步尝试。# 给左表的字段加索引 create index cid_teacher2 on teacher2(cid); # 查看执行计划 explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';结果如下:当然你可以下去接着优化,给cname添加一个索引。索引优化是一个逐步的过程,需要一点点尝试。# 给cname的字段加索引 create index cname_course2 on course2(cname); # 查看执行计划 explain select t.cid,c.cname from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';结果如下:最后补充一个:Using join buffer是extra中的一个选项,表示Mysql引擎使用了“连接缓存”,即MySQL底层动了你的SQL,你写的太差了。4)三表优化大于等于张表,优化原则一样小表驱动大表索引建立在经常查询的字段上7、避免索引失效的一些原则① 复合索引需要注意的点复合索引,不要跨列或无序使用(最佳左前缀)复合索引,尽量使用全索引匹配,也就是说,你建立几个索引,就使用几个索引② 不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效explain select * from book where authorid = 1 and typeid = 2; explain select * from book where authorid*2 = 1 and typeid = 2 ;结果如下:③ 索引不能使用不等于(!= <>)或is null (is not null),否则自身以及右侧所有全部失效(针对大多数情况)。复合索引中如果有>,则自身和右侧索引全部失效。# 针对不是复合索引的情况 explain select * from book where authorid != 1 and typeid =2 ; explain select * from book where authorid != 1 and typeid !=2 ;结果如下:再观看下面这个案例:# 删除单独的索引 drop index authorid_index on book; drop index typeid_index on book; # 创建一个复合索引 alter table book add index idx_book_at (authorid,typeid); # 查看执行计划 explain select * from book where authorid > 1 and typeid = 2 ; explain select * from book where authorid = 1 and typeid > 2 ;结果如下:结论:复合索引中如果有【>】,则自身和右侧索引全部失效。在看看复合索引中有【<】的情况:我们学习索引优化 ,是一个大部分情况适用的结论,但由于SQL优化器等原因 该结论不是100%正确。一般而言, 范围查询(> < in),之后的索引失效。④ SQL优化,是一种概率层面的优化。至于是否实际使用了我们的优化,需要通过explain进行推测。# 删除复合索引 drop index authorid_typeid_bid on book; # 为authorid和typeid,分别创建索引 create index authorid_index on book(authorid); create index typeid_index on book(typeid); # 查看执行计划 explain select * from book where authorid = 1 and typeid =2 ;结果如下:结果分析: 我们创建了两个索引,但是实际上只使用了一个索引。因为对于两个单独的索引,程序觉得只用一个索引就够了,不需要使用两个。当我们创建一个复合索引,再次执行上面的SQL:# 查看执行计划 explain select * from book where authorid = 1 and typeid =2 ;结果如下:⑤ 索引覆盖,百分之百没问题⑥ like尽量以“常量”开头,不要以’%'开头,否则索引失效explain select * from teacher where tname like "%x%" ; explain select * from teacher where tname like 'x%'; explain select tname from teacher where tname like '%x%';结果如下:结论如下: like尽量不要使用类似"%x%"情况,但是可以使用"x%"情况。如果非使用 "%x%"情况,需要使用索引覆盖。⑦ 尽量不要使用类型转换(显示、隐式),否则索引失效explain select * from teacher where tname = 'abc' ; explain select * from teacher where tname = 123 ;结果如下:⑧ 尽量不要使用or,否则索引失效explain select * from teacher where tname ='' and tcid >1 ; explain select * from teacher where tname ='' or tcid >1 ;结果如下:注意:or很猛,会让自身索引和左右两侧的索引都失效。8、一些其他的优化方法1)exists和in的优化如果主查询的数据集大,则使用i关键字,效率高。如果子查询的数据集大,则使用exist关键字,效率高。select ..from table where exist (子查询) ; select ..from table where 字段 in (子查询) ;2)order by优化IO就是访问硬盘文件的次数using filesort 有两种算法:双路排序、单路排序(根据IO的次数)MySQL4.1之前默认使用双路排序;双路:扫描2次磁盘(1:从磁盘读取排序字段,对排序字段进行排序(在buffer中进行的排序)2:扫描其他字段)MySQL4.1之后默认使用单路排序:只读取一次(全部字段),在buffer中进行排序。但种单路排序会有一定的隐患(不一定真的是“单路/1次IO”,有可能多次IO)。原因:如果数据量特别大,则无法将所有字段的数据一次性读取完毕,因此会进行“分片读取、多次读取”。注意:单路排序 比双路排序 会占用更多的buffer。单路排序在使用时,如果数据大,可以考虑调大buffer的容量大小:# 不一定真的是“单路/1次IO”,有可能多次IO set max_length_for_sort_data = 1024 如果max_length_for_sort_data值太低,则mysql会自动从 单路->双路(太低:需要排序的列的总大小超过了max_length_for_sort_data定义的字节数)① 提高order by查询的策略:选择使用单路、双路 ;调整buffer的容量大小避免使用select …(select后面写所有字段,也比写效率高)复合索引,不要跨列使用 ,避免using filesort保证全部的排序字段,排序的一致性(都是升序或降序)
1.8w 字详解 SQL 优化 分享一篇关于SQL优化的硬核文章,全文有点长,建议收藏后慢慢看。很多朋友在做数据分析时,分析两分钟,跑数两小时?在使用SQL过程中不仅要关注数据结果,同样要注意SQL语句的执行效率。本文涉及三部分:SQL介绍SQL优化方法SQL优化实例1、MySQL的基本架构1)MySQL的基础架构图左边的client可以看成是客户端,客户端有很多,像我们经常你使用的CMD黑窗口,像我们经常用于学习的WorkBench,像企业经常使用的Navicat工具,它们都是一个客户端。右边的这一大堆都可以看成是Server(MySQL的服务端),我们将Server在细分为sql层和存储引擎层。当查询出数据以后,会返回给执行器。执行器一方面将结果写到查询缓存里面,当你下次再次查询的时候,就可以直接从查询缓存中获取到数据了。另一方面,直接将结果响应回客户端。2)查询数据库的引擎① show engines;② show variables like “%storage_engine%”;3)指定数据库对象的存储引擎create table tb( id int(4) auto_increment, name varchar(5), dept varchar(5), primary key(id) ) engine=myISAM auto_increment=1 default charset=utf8;SQL优化1)为什么需要进行SQL优化?在进行多表连接查询、子查询等操作的时候,由于你写出的SQL语句欠佳,导致的服务器执行时间太长,我们等待结果的时间太长。基于此,我们需要学习怎么优化SQL。2)mysql的编写过程和解析过程① 编写过程select dinstinct ..from ..join ..on ..where ..group by ..having ..order by ..limit ..② 解析过程from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..提供一个网站,详细说明了mysql解析过程:https://www.cnblogs.com/annsshadow/p/5037667.html3)SQL优化—主要就是优化索引优化SQL,最重要的就是优化SQL索引。索引相当于字典的目录。利用字典目录查找汉字的过程,就相当于利用SQL索引查找某条记录的过程。有了索引,就可以很方便快捷的定位某条记录。① 什么是索引?索引就是帮助MySQL高效获取数据的一种【数据结构】。索引是一种树结构,MySQL中一般用的是【B+树】。② 索引图示说明(这里用二叉树来帮助我们理解索引)树形结构的特点是:子元素比父元素小的,放在左侧;子元素比父元素大的,放在右侧。这个图示只是为了帮我们简单理解索引的,真实的关于【B+树】的说明,我们会在下面进行说明。索引是怎么查找数据的呢?两个字【指向】,上图中我们给age列指定了一个索引,即类似于右侧的这种树形结构。mysql表中的每一行记录都有一个硬件地址,例如索引中的age=50,指向的就是源表中该行的标识符(“硬件地址”)。也就是说,树形索引建立了与源表中每行记录硬件地址的映射关系,当你指定了某个索引,这种映射关系也就建成了,这就是为什么我们可以通过索引快速定位源表中记录的原因。以【select * from student where age=33】查询语句为例。当我们不加索引的时候,会从上到下扫描源表,当扫描到第5行的时候,找到了我们想要找到了元素,一共是查询了5次。当添加了索引以后,就直接在树形结构中进行查找,33比50小,就从左侧查询到了23,33大于23,就又查询到了右侧,这下找到了33,整个索引结束,一共进行了3次查找。是不是很方便,假如我们此时需要查找age=62,你再想想“添加索引”前后,查找次数的变化情况。4)索引的弊端1.当数据量很大的时候,索引也会很大(当然相比于源表来说,还是相当小的),也需要存放在内存/硬盘中(通常存放在硬盘中),占据一定的内存空间/物理空间。2.索引并不适用于所有情况:a.少量数据;b.频繁进行改动的字段,不适合做索引;c.很少使用的字段,不需要加索引;3.索引会提高数据查询效率,但是会降低“增、删、改”的效率。当不使用索引的时候,我们进行数据的增删改,只需要操作源表即可,但是当我们添加索引后,不仅需要修改源表,也需要再次修改索引,很麻烦。尽管是这样,添加索引还是很划算的,因为我们大多数使用的就是查询,“查询”对于程序的性能影响是很大的。5)索引的优势1.提高查询效率(降低了IO使用率)。当创建了索引后,查询次数减少了。2.降低CPU使用率。比如说【…order by age desc】这样一个操作,当不加索引,会把源表加载到内存中做一个排序操作,极大的消耗了资源。但是使用了索引以后,第一索引本身就小一些,第二索引本身就是排好序的,左边数据最小,右边数据最大。6)B+树图示说明MySQL中索引使用的就是B+树结构。关于B+树的说明:首先,Btree一般指的都是【B+树】,数据全部存放在叶子节点中。对于上图来说,最下面的第3层,属于叶子节点,真实数据部份都是存放在叶子节点当中的。那么对于第1、2层中的数据又是干嘛的呢?答:用于分割指针块儿的,比如说小于26的找P1,介于26-30之间的找P2,大于30的找P3。其次,三层【B+树】可以存放上百万条数据。这么多数据怎么放的呢?增加“节点数”。图中我们只有三个节点。最后,【B+树】中查询任意数据的次数,都是n次,n表示的是【B+树】的高度。3、索引的分类与创建1)索引分类单值索引唯一索引复合索引① 单值索引利用表中的某一个字段创建单值索引。一张表中往往有多个字段,也就是说每一列其实都可以创建一个索引,这个根据我们实际需求来进行创建。还需要注意的一点就是,一张表可以创建多个“单值索引”。假如某一张表既有age字段,又有name字段,我们可以分别对age、name创建一个单值索引,这样一张表就有了两个单值索引。② 唯一索引也是利用表中的某一个字段创建单值索引,与单值索引不同的是:创建唯一索引的字段中的数据,不能有重复值。像age肯定有很多人的年龄相同,像name肯定有些人是重名的,因此都不适合创建“唯一索引”。像编号id、学号sid,对于每个人都不一样,因此可以用于创建唯一索引。③ 复合索引多个列共同构成的索引。比如说我们创建这样一个“复合索引”(name,age),先利用name进行索引查询,当name相同的时候,我们利用age再进行一次筛选。注意:复合索引的字段并不是非要都用完,当我们利用name字段索引出我们想要的结果以后,就不需要再使用age进行再次筛选了。2)创建索引① 语法语法:create 索引类型 索引名 on 表(字段);建表语句如下:查询表结构如下:② 创建索引的第一种方式Ⅰ 创建单值索引create index dept_index on tb(dept);Ⅱ 创建唯一索引:这里我们假定name字段中的值都是唯一的create unique index name_index on tb(name);Ⅲ 创建复合索引create index dept_name_index on tb(dept,name);③ 创建索引的第二种方式先删除之前创建的索引以后,再进行这种创建索引方式的测试;语法:alter table 表名 add 索引类型 索引名(字段)Ⅰ 创建单值索引alter table tb add index dept_index(dept);Ⅱ 创建唯一索引:这里我们假定name字段中的值都是唯一的alter table tb add unique index name_index(name);Ⅲ 创建复合索引alter table tb add index dept_name_index(dept,name);④ 补充说明如果某个字段是primary key,那么该字段默认就是主键索引。主键索引和唯一索引非常相似。相同点:该列中的数据都不能有相同值;不同点:主键索引不能有null值,但是唯一索引可以有null值。3)索引删除和索引查询① 索引删除语法:drop index 索引名 on 表名;drop index name_index on tb;② 索引查询语法:show index from 表名;show index from tb;结果如下:4、SQL性能问题的探索人为优化: 需要我们使用explain分析SQL的执行计划。该执行计划可以模拟SQL优化器执行SQL语句,可以帮助我们了解到自己编写SQL的好坏。SQL优化器自动优化: 最开始讲述MySQL执行原理的时候,我们已经知道MySQL有一个优化器,当你写了一个SQL语句的时候,SQL优化器如果认为你写的SQL语句不够好,就会自动写一个好一些的等价SQL去执行。SQL优化器自动优化功能【会干扰】我们的人为优化功能。当我们查看了SQL执行计划以后,如果写的不好,我们会去优化自己的SQL。当我们以为自己优化的很好的时候,最终的执行计划,并不是按照我们优化好的SQL语句来执行的,而是有时候将我们优化好的SQL改变了,去执行。SQL优化是一种概率问题,有时候系统会按照我们优化好的SQL去执行结果(优化器觉得你写的差不多,就不会动你的SQL)。有时候优化器仍然会修改我们优化好的SQL,然后再去执行。1)查看执行计划语法:explain + SQL语句eg:explain select * from tb;2)“执行计划”中需要知道的几个“关键字”id :编号select_type :查询类型table :表type :类型possible_keys :预测用到的索引key :实际使用的索引key_len :实际使用索引的长度ref :表之间的引用rows :通过索引查询到的数据量Extra :额外的信息建表语句和插入数据:# 建表语句 create table course ( cid int(3), cname varchar(20), tid int(3) ); create table teacher ( tid int(3), tname varchar(20), tcid int(3) ); create table teacherCard ( tcid int(3), tcdesc varchar(200) ); # 插入数据 insert into course values(1,'java',1); insert into course values(2,'html',1); insert into course values(3,'sql',2); insert into course values(4,'web',3); insert into teacher values(1,'tz',1); insert into teacher values(2,'tw',2); insert into teacher values(3,'tl',3); insert into teacherCard values(1,'tzdesc') ; insert into teacherCard values(2,'twdesc') ; insert into teacherCard values(3,'tldesc') ;explain执行计划常用关键字详解1)id关键字的使用说明① 案例:查询课程编号为2 或 教师证编号为3 的老师信息:# 查看执行计划 explain select t.* from teacher t,course c,teacherCard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3);结果如下:接着,在往teacher表中增加几条数据。insert into teacher values(4,'ta',4); insert into teacher values(5,'tb',5); insert into teacher values(6,'tc',6);再次查看执行计划。# 查看执行计划 explain select t.* from teacher t,course c,teacherCard tc where t.tid = c.tid and t.tcid = tc.tcid and (c.cid = 2 or tc.tcid = 3);结果如下:表的执行顺序 ,因表数量改变而改变的原因:笛卡尔积。a b c 2 3 4 最终:2 * 3 * 4 = 6 * 4 = 24 c b a 4 3 2 最终:4 * 3 * 2 = 12 * 2 = 24分析:最终执行的条数,虽然是一致的。但是中间过程,有一张临时表是6,一张临时表是12,很明显6 < 12,对于内存来说,数据量越小越好,因此优化器肯定会选择第一种执行顺序。结论:id值相同,从上往下顺序执行。表的执行顺序因表数量的改变而改变。② 案例:查询教授SQL课程的老师的描述(desc)# 查看执行计划 explain select tc.tcdesc from teacherCard tc where tc.tcid = ( select t.tcid from teacher t where t.tid = (select c.tid from course c where c.cname = 'sql') );结果如下:结论:id值不同,id值越大越优先查询。这是由于在进行嵌套子查询时,先查内层,再查外层。③ 针对②做一个简单的修改# 查看执行计划 explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid and t.tid = (select c.tid from course c where cname = 'sql') ;结果如下:结论:id值有相同,又有不同。id值越大越优先;id值相同,从上往下顺序执行。2)select_type关键字的使用说明:查询类型① simple:简单查询不包含子查询,不包含union查询。explain select * from teacher;结果如下:② primary:包含子查询的主查询(最外层)③ subquery:包含子查询的主查询(非最外层)④ derived:衍生查询(用到了临时表)a.在from子查询中,只有一张表;b.在from子查询中,如果table1 union table2,则table1就是derived表;explain select cr.cname from ( select * from course where tid = 1 union select * from course where tid = 2 ) cr ;结果如下:⑤ union:union之后的表称之为union表,如上例⑥ union result:告诉我们,哪些表之间使用了union查询3)type关键字的使用说明:索引类型system、const只是理想状况,实际上只能优化到index --> range --> ref这个级别。要对type进行优化的前提是,你得创建索引。① system源表只有一条数据(实际中,基本不可能);衍生表只有一条数据的主查询(偶尔可以达到)。② const仅仅能查到一条数据的SQL ,仅针对Primary key或unique索引类型有效。explain select tid from test01 where tid =1 ;结果如下:删除以前的主键索引后,此时我们添加一个其他的普通索引:create index test01_index on test01(tid) ; # 再次查看执行计划 explain select tid from test01 where tid =1 ;结果如下:③ eq_ref唯一性索引,对于每个索引键的查询,返回匹配唯一行数据(有且只有1个,不能多 、不能0),并且查询结果和数据条数必须一致。此种情况常见于唯一索引和主键索引。delete from teacher where tcid >= 4; alter table teacherCard add constraint pk_tcid primary key(tcid); alter table teacher add constraint uk_tcid unique index(tcid) ; explain select t.tcid from teacher t,teacherCard tc where t.tcid = tc.tcid ;结果如下:总结:以上SQL,用到的索引是t.tcid,即teacher表中的tcid字段;如果teacher表的数据个数和连接查询的数据个数一致(都是3条数据),则有可能满足eq_ref级别;否则无法满足。条件很苛刻,很难达到。④ ref非唯一性索引,对于每个索引键的查询,返回匹配的所有行(可以0,可以1,可以多)准备数据:创建索引,并查看执行计划:# 添加索引 alter table teacher add index index_name (tname) ; # 查看执行计划 explain select * from teacher where tname = 'tz';结果如下:⑤ range检索指定范围的行 ,where后面是一个范围查询(between, >, <, >=, in)in有时候会失效,从而转为无索引时候的ALL# 添加索引 alter table teacher add index tid_index (tid) ; # 查看执行计划:以下写了一种等价SQL写法,查看执行计划 explain select t.* from teacher t where t.tid in (1,2) ; explain select t.* from teacher t where t.tid <3 ;结果如下:⑥ index查询全部索引中的数据(扫描整个索引)⑦ ALL查询全部源表中的数据(暴力扫描全表)注意:cid是索引字段,因此查询索引字段,只需要扫描索引表即可。但是tid不是索引字段,查询非索引字段,需要暴力扫描整个源表,会消耗更多的资源。4)possible_keys和keypossible_keys可能用到的索引。是一种预测,不准。了解一下就好。key指的是实际使用的索引。# 先给course表的cname字段,添加一个索引 create index cname_index on course(cname); # 查看执行计划 explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid and t.tid = (select c.tid from course c where cname = 'sql') ;结果如下:有一点需要注意的是:如果possible_key/key是NULL,则说明没用索引。5)key_len索引的长度,用于判断复合索引是否被完全使用(a,b,c)。① 新建一张新表,用于测试# 创建表 create table test_kl ( name char(20) not null default '' ); # 添加索引 alter table test_kl add index index_name(name) ; # 查看执行计划 explain select * from test_kl where name ='' ; 结果如下:结果分析:因为我没有设置服务端的字符集,因此默认的字符集使用的是latin1,对于latin1一个字符代表一个字节,因此这列的key_len的长度是20,表示使用了name这个索引。② 给test_kl表,新增name1列,该列没有设置“not null”结果如下:结果分析:如果索引字段可以为null,则mysql底层会使用1个字节用于标识。③ 删除原来的索引name和name1,新增一个复合索引# 删除原来的索引name和name1 drop index index_name on test_kl ; drop index index_name1 on test_kl ; # 增加一个复合索引 create index name_name1_index on test_kl(name,name1); # 查看执行计划 explain select * from test_kl where name1 = '' ; --121 explain select * from test_kl where name = '' ; --60结果如下:结果分析: 对于下面这个执行计划,可以看到我们只使用了复合索引的第一个索引字段name,因此key_len是20,这个很清楚。再看上面这个执行计划,我们虽然仅仅在where后面使用了复合索引字段中的name1字段,但是你要使用复合索引的第2个索引字段,会默认使用了复合索引的第1个索引字段name,由于name1可以是null,因此key_len = 20 + 20 + 1 = 41呀!④ 再次怎加一个name2字段,并为该字段创建一个索引。不同的是:该字段数据类型是varchar# 新增一个字段name2,name2可以为null alter table test_kl add column name2 varchar(20) ; # 给name2字段,设置为索引字段 alter table test_kl add index name2_index(name2) ; # 查看执行计划 explain select * from test_kl where name2 = '' ; 结果如下:结果分析: key_len = 20 + 1 + 2,这个20 + 1我们知道,这个2又代表什么呢?原来varchar属于可变长度,在mysql底层中,用2个字节标识可变长度。6)ref这里的ref的作用,指明当前表所参照的字段。注意与type中的ref值区分。在type中,ref只是type类型的一种选项值。# 给course表的tid字段,添加一个索引 create index tid_index on course(tid); # 查看执行计划 explain select * from course c,teacher t where c.tid = t.tid and t.tname = 'tw';结果如下:结果分析: 有两个索引,c表的c.tid引用的是t表的tid字段,因此可以看到显示结果为【数据库名.t.tid】,t表的t.name引用的是一个常量"tw",因此可以看到结果显示为const,表示一个常量。7)rows(这个目前还是有点疑惑)被索引优化查询的数据个数 (实际通过索引而查询到的数据个数)explain select * from course c,teacher t where c.tid = t.tid and t.tname = 'tz' ;结果如下:8)extra表示其他的一些说明,也很有用。① using filesort:针对单索引的情况当出现了这个词,表示你当前的SQL性能消耗较大。表示进行了一次“额外”的排序。常见于order by语句中。Ⅰ 什么是“额外”的排序?为了讲清楚这个,我们首先要知道什么是排序。我们为了给某一个字段进行排序的时候,首先你得先查询到这个字段,然后在将这个字段进行排序。紧接着,我们查看如下两个SQL语句的执行计划。# 新建一张表,建表同时创建索引 create table test02 ( a1 char(3), a2 char(3), a3 char(3), index idx_a1(a1), index idx_a2(a2), index idx_a3(a3) ); # 查看执行计划 explain select * from test02 where a1 ='' order by a1 ; explain select * from test02 where a1 ='' order by a2 ; 结果如下:结果分析: 对于第一个执行计划,where后面我们先查询了a1字段,然后再利用a1做了依次排序,这个很轻松。但是对于第二个执行计划,where后面我们查询了a1字段,然而利用的却是a2字段进行排序,此时myql底层会进行一次查询,进行“额外”的排序。总结:对于单索引,如果排序和查找是同一个字段,则不会出现using filesort;如果排序和查找不是同一个字段,则会出现using filesort;因此where哪些字段,就order by哪些些字段。② using filesort:针对复合索引的情况不能跨列(官方术语:最佳左前缀)# 删除test02的索引 drop index idx_a1 on test02; drop index idx_a2 on test02; drop index idx_a3 on test02; # 创建一个复合索引 alter table test02 add index idx_a1_a2_a3 (a1,a2,a3) ; # 查看下面SQL语句的执行计划 explain select *from test02 where a1='' order by a3 ; --using filesort explain select *from test02 where a2='' order by a3 ; --using filesort explain select *from test02 where a1='' order by a2 ;结果如下:结果分析: 复合索引的顺序是(a1,a2,a3),可以看到a1在最左边,因此a1就叫做“最佳左前缀”,如果要使用后面的索引字段,必须先使用到这个a1字段。对于explain1,where后面我们使用a1字段,但是后面的排序使用了a3,直接跳过了a2,属于跨列;对于explain2,where后面我们使用了a2字段,直接跳过了a1字段,也属于跨列;对于explain3,where后面我们使用a1字段,后面使用的是a2字段,因此没有出现【using filesort】。③ using temporary当出现了这个词,也表示你当前的SQL性能消耗较大。这是由于当前SQL用到了临时表。一般出现在group by中。explain select a1 from test02 where a1 in ('1','2','3') group by a1 ; explain select a1 from test02 where a1 in ('1','2','3') group by a2 ; --using temporary结果如下:结果分析: 当你查询哪个字段,就按照那个字段分组,否则就会出现using temporary。针对using temporary,我们在看一个例子:using temporary表示需要额外再使用一张表,一般出现在group by语句中。虽然已经有表了,但是不适用,必须再来一张表。再次来看mysql的编写过程和解析过程。Ⅰ 编写过程select dinstinct ..from ..join ..on ..where ..group by ..having ..order by ..limit ..Ⅱ 解析过程from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..很显然,where后是group by,然后才是select。基于此,我们再查看如下两个SQL语句的执行计划。explain select * from test03 where a2=2 and a4=4 group by a2,a4; explain select * from test03 where a2=2 and a4=4 group by a3;分析如下: 对于第一个执行计划,where后面是a2和a4,接着我们按照a2和a4分组,很明显这两张表已经有了,直接在a2和a4上分组就行了。但是对于第二个执行计划,where后面是a2和a4,接着我们却按照a3分组,很明显我们没有a3这张表,因此有需要再来一张临时表a3。因此就会出现using temporary。④ using index当你看到这个关键词,恭喜你,表示你的SQL性能提升了。using index称之为“索引覆盖”。当出现了using index,就表示不用读取源表,而只利用索引获取数据,不需要回源表查询。只要使用到的列,全部出现在索引中,就是索引覆盖。# 删除test02中的复合索引idx_a1_a2_a3 drop index idx_a1_a2_a3 on test02; # 重新创建一个复合索引 idx_a1_a2create index idx_a1_a2 on test02(a1,a2); # 查看执行计划 explain select a1,a3 from test02 where a1='' or a3= '' ; explain select a1,a2 from test02 where a1='' and a2= '' ;结果如下:结果分析: 我们创建的是a1和a2的复合索引,对于第一个执行计划,我们却出现了a3,该字段并没有创建索引,因此没有出现using index,而是using where,表示我们需要回表查询。对于第二个执行计划,属于完全的索引覆盖,因此出现了using index。针对using index,我们在查看一个案例:explain select a1,a2 from test02 where a1='' or a2= '' ; explain select a1,a2 from test02;结果如下:如果用到了索引覆盖(using index时),会对possible_keys和key造成影响:a.如果没有where,则索引只出现在key中;b.如果有where,则索引 出现在key和possible_keys中。⑤ using where表示需要【回表查询】,表示既在索引中进行了查询,又回到了源表进行了查询。# 删除test02中的复合索引idx_a1_a2 drop index idx_a1_a2 on test02; # 将a1字段,新增为一个索引 create index a1_index on test02(a1); # 查看执行计划 explain select a1,a3 from test02 where a1="" and a3="" ;结果如下:结果分析: 我们既使用了索引a1,表示我们使用了索引进行查询。但是又对于a3字段,我们并没有使用索引,因此对于a3字段,需要回源表查询,这个时候出现了using where。⑥ impossible where(了解)当where子句永远为False的时候,会出现impossible where# 查看执行计划 explain select a1 from test02 where a1="a" and a1="b" ;结果如下:6、优化示例1)引入案例# 创建新表 create table test03 ( a1 int(4) not null, a2 int(4) not null, a3 int(4) not null, a4 int(4) not null ); # 创建一个复合索引 create index a1_a2_a3_test03 on test03(a1,a2,a3); # 查看执行计划 explain select a3 from test03 where a1=1 and a2=2 and a3=3;结果如下:推荐写法: 复合索引顺序和使用顺序一致。下面看看【不推荐写法】:复合索引顺序和使用顺序不一致。# 查看执行计划 explain select a3 from test03 where a3=1 and a2=2 and a1=3;结果如下:结果分析: 虽然结果和上述结果一致,但是不推荐这样写。但是这样写怎么又没有问题呢?这是由于SQL优化器的功劳,它帮我们调整了顺序。最后再补充一点:对于复合索引,不要跨列使用# 查看执行计划 explain select a3 from test03 where a1=1 and a3=2 group by a3;结果如下:结果分析: a1_a2_a3是一个复合索引,我们使用a1索引后,直接跨列使用了a3,直接跳过索引a2,因此索引a3失效了,当使用a3进行分组的时候,就会出现using where。2)单表优化# 创建新表 create table book ( bid int(4) primary key, name varchar(20) not null, authorid int(4) not null, publicid int(4) not null, typeid int(4) not null ); # 插入数据 insert into book values(1,'tjava',1,1,2) ; insert into book values(2,'tc',2,1,2) ; insert into book values(3,'wx',3,2,1) ; insert into book values(4,'math',4,2,3) ; 结果如下:案例:查询authorid=1且typeid为2或3的bid,并根据typeid降序排列。explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ; 结果如下:这是没有进行任何优化的SQL,可以看到typ为ALL类型,extra为using filesort,可以想象这个SQL有多恐怖。优化:添加索引的时候,要根据MySQL解析顺序添加索引,又回到了MySQL的解析顺序,下面我们再来看看MySQL的解析顺序。from .. on.. join ..where ..group by ..having ..select dinstinct ..order by ..limit ..① 优化1:基于此,我们进行索引的添加,并再次查看执行计划。# 添加索引 create index typeid_authorid_bid on book(typeid,authorid,bid); # 再次查看执行计划 explain select bid from book where typeid in(2,3) and authorid=1 order by typeid desc ;结果如下:结果分析: 结果并不是和我们想象的一样,还是出现了using where,查看索引长度key_len=8,表示我们只使用了2个索引,有一个索引失效了。② 优化2:使用了in有时候会导致索引失效,基于此有了如下一种优化思路。将in字段放在最后面。需要注意一点:每次创建新的索引的时候,最好是删除以前的废弃索引,否则有时候会产生干扰(索引之间)。# 删除以前的索引 drop index typeid_authorid_bid on book; # 再次创建索引 create index authorid_typeid_bid on book(authorid,typeid,bid); # 再次查看执行计划 explain select bid from book where authorid=1 and typeid in(2,3) order by typeid desc ;结果如下:结果分析: 这里虽然没有变化,但是这是一种优化思路。总结如下:a.最佳做前缀,保持索引的定义和使用的顺序一致性b.索引需要逐步优化(每次创建新索引,根据情况需要删除以前的废弃索引)c.将含In的范围查询,放到where条件的最后,防止失效。本例中同时出现了Using where(需要回原表); Using index(不需要回原表):原因,where authorid=1 and typeid in(2,3)中authorid在索引(authorid,typeid,bid)中,因此不需要回原表(直接在索引表中能查到);而typeid虽然也在索引(authorid,typeid,bid)中,但是含in的范围查询已经使该typeid索引失效,因此相当于没有typeid这个索引,所以需要回原表(using where);例如以下没有了In,则不会出现using where:explain select bid from book where authorid=1 and typeid =3 order by typeid desc ;结果如下:3)两表优化# 创建teacher2新表 create table teacher2 ( tid int(4) primary key, cid int(4) not null ); # 插入数据 insert into teacher2 values(1,2); insert into teacher2 values(2,1); insert into teacher2 values(3,3); # 创建course2新表 create table course2 ( cid int(4) , cname varchar(20) ); # 插入数据 insert into course2 values(1,'java'); insert into course2 values(2,'python'); insert into course2 values(3,'kotlin');案例:使用一个左连接,查找教java课程的所有信息。explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';结果如下:① 优化对于两张表,索引往哪里加?答:对于表连接,小表驱动大表。索引建立在经常使用的字段上。为什么小表驱动大表好一些呢? 小表:10 大表:300 # 小表驱动大表 select ...where 小表.x10=大表.x300 ; for(int i=0;i<小表.length10;i++) { for(int j=0;j<大表.length300;j++) { ... } } # 大表驱动小表 select ...where 大表.x300=小表.x10 ; for(int i=0;i<大表.length300;i++) { for(int j=0;j<小表.length10;j++) { ... } }分析: 以上2个FOR循环,最终都会循环3000次;但是对于双层循环来说:一般建议,将数据小的循环,放外层。数据大的循环,放内层。不用管这是为什么,这是编程语言的一个原则,对于双重循环,外层循环少,内存循环大,程序的性能越高。结论:当编写【…on t.cid=c.cid】时,将数据量小的表放左边(假设此时t表数据量小,c表数据量大。)我们已经知道了,对于两表连接,需要利用小表驱动大表,例如【…on t.cid=c.cid】,t如果是小表(10条),c如果是大表(300条),那么t每循环1次,就需要循环300次,即t表的t.cid字段属于,经常使用的字段,因此需要给cid字段添加索引。更深入的说明: 一般情况下,左连接给左表加索引。右连接给右表加索引。其他表需不需要加索引,我们逐步尝试。# 给左表的字段加索引 create index cid_teacher2 on teacher2(cid); # 查看执行计划 explain select * from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';结果如下:当然你可以下去接着优化,给cname添加一个索引。索引优化是一个逐步的过程,需要一点点尝试。# 给cname的字段加索引 create index cname_course2 on course2(cname); # 查看执行计划 explain select t.cid,c.cname from teacher2 t left outer join course2 c on t.cid=c.cid where c.cname='java';结果如下:最后补充一个:Using join buffer是extra中的一个选项,表示Mysql引擎使用了“连接缓存”,即MySQL底层动了你的SQL,你写的太差了。4)三表优化大于等于张表,优化原则一样小表驱动大表索引建立在经常查询的字段上7、避免索引失效的一些原则① 复合索引需要注意的点复合索引,不要跨列或无序使用(最佳左前缀)复合索引,尽量使用全索引匹配,也就是说,你建立几个索引,就使用几个索引② 不要在索引上进行任何操作(计算、函数、类型转换),否则索引失效explain select * from book where authorid = 1 and typeid = 2; explain select * from book where authorid*2 = 1 and typeid = 2 ;结果如下:③ 索引不能使用不等于(!= <>)或is null (is not null),否则自身以及右侧所有全部失效(针对大多数情况)。复合索引中如果有>,则自身和右侧索引全部失效。# 针对不是复合索引的情况 explain select * from book where authorid != 1 and typeid =2 ; explain select * from book where authorid != 1 and typeid !=2 ;结果如下:再观看下面这个案例:# 删除单独的索引 drop index authorid_index on book; drop index typeid_index on book; # 创建一个复合索引 alter table book add index idx_book_at (authorid,typeid); # 查看执行计划 explain select * from book where authorid > 1 and typeid = 2 ; explain select * from book where authorid = 1 and typeid > 2 ;结果如下:结论:复合索引中如果有【>】,则自身和右侧索引全部失效。在看看复合索引中有【<】的情况:我们学习索引优化 ,是一个大部分情况适用的结论,但由于SQL优化器等原因 该结论不是100%正确。一般而言, 范围查询(> < in),之后的索引失效。④ SQL优化,是一种概率层面的优化。至于是否实际使用了我们的优化,需要通过explain进行推测。# 删除复合索引 drop index authorid_typeid_bid on book; # 为authorid和typeid,分别创建索引 create index authorid_index on book(authorid); create index typeid_index on book(typeid); # 查看执行计划 explain select * from book where authorid = 1 and typeid =2 ;结果如下:结果分析: 我们创建了两个索引,但是实际上只使用了一个索引。因为对于两个单独的索引,程序觉得只用一个索引就够了,不需要使用两个。当我们创建一个复合索引,再次执行上面的SQL:# 查看执行计划 explain select * from book where authorid = 1 and typeid =2 ;结果如下:⑤ 索引覆盖,百分之百没问题⑥ like尽量以“常量”开头,不要以’%'开头,否则索引失效explain select * from teacher where tname like "%x%" ; explain select * from teacher where tname like 'x%'; explain select tname from teacher where tname like '%x%';结果如下:结论如下: like尽量不要使用类似"%x%"情况,但是可以使用"x%"情况。如果非使用 "%x%"情况,需要使用索引覆盖。⑦ 尽量不要使用类型转换(显示、隐式),否则索引失效explain select * from teacher where tname = 'abc' ; explain select * from teacher where tname = 123 ;结果如下:⑧ 尽量不要使用or,否则索引失效explain select * from teacher where tname ='' and tcid >1 ; explain select * from teacher where tname ='' or tcid >1 ;结果如下:注意:or很猛,会让自身索引和左右两侧的索引都失效。8、一些其他的优化方法1)exists和in的优化如果主查询的数据集大,则使用i关键字,效率高。如果子查询的数据集大,则使用exist关键字,效率高。select ..from table where exist (子查询) ; select ..from table where 字段 in (子查询) ;2)order by优化IO就是访问硬盘文件的次数using filesort 有两种算法:双路排序、单路排序(根据IO的次数)MySQL4.1之前默认使用双路排序;双路:扫描2次磁盘(1:从磁盘读取排序字段,对排序字段进行排序(在buffer中进行的排序)2:扫描其他字段)MySQL4.1之后默认使用单路排序:只读取一次(全部字段),在buffer中进行排序。但种单路排序会有一定的隐患(不一定真的是“单路/1次IO”,有可能多次IO)。原因:如果数据量特别大,则无法将所有字段的数据一次性读取完毕,因此会进行“分片读取、多次读取”。注意:单路排序 比双路排序 会占用更多的buffer。单路排序在使用时,如果数据大,可以考虑调大buffer的容量大小:# 不一定真的是“单路/1次IO”,有可能多次IO set max_length_for_sort_data = 1024 如果max_length_for_sort_data值太低,则mysql会自动从 单路->双路(太低:需要排序的列的总大小超过了max_length_for_sort_data定义的字节数)① 提高order by查询的策略:选择使用单路、双路 ;调整buffer的容量大小避免使用select …(select后面写所有字段,也比写效率高)复合索引,不要跨列使用 ,避免using filesort保证全部的排序字段,排序的一致性(都是升序或降序) -
SQL优化技巧 SQL优化是一个大家都比较关注的热门问题,无论在面试,还是工作中,都很有可能会遇到。1、避免使用 select *很多时候,我们写sql语句时,为了方便,喜欢直接使用 select * ,一次性查处所有列的数据。反例:select * from user where id=1;在实际业务场景中,可能我们需要的只是那么几个指定列的数据,并不需要全部。查了所有的数据,但是不用,就会白白浪费数据库资源,比如内存或者CPU。另外,多查出来的数据,通过网络 I/O 传输的过程中,也会增加数据传输的时间。还有一个问题就是,select * 不会走 覆盖索引 ,会出现大量的 回表 操作,从而导致查询sql的性能降低。应该如何优化,正例:select name,age from user where id=1;优化思路就是只查出需要用到的列,多余的列根本无需查出来。2、用union all 代替 unionSQL语句使用 union 关键字以后,可以获取重排后的数据。而如果使用 union all 关键字,可以获取所有数据,包含重复的数据。反例:(select * from user where id=1) union (select * from user where id=1);重排的过程是需要遍历,排序和比较的,它更加耗时,更消耗CPU资源。所以如果可以使用 union all 就尽量不使用 union。(select * from user where id=1) union all (select * from user where id=1);除非有一些特殊场景,比如话 union all 之后结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这是可以使用 union。3、小表驱动大表小表驱动大表的意思就是说,用小表的数据集驱动大表的数据集。具体怎么操作呢?假如现在有 order 和 user 两张表,其中 order 表有10000条数据,而 user 表只有100 条数据。这时如果想查看一下,所有有效用户成功下单的订单列表。可以使用 in 关键字实现:select * from order where user_id in (select id from user where status=1);或者使用 exists 关键字实现:select * from order where exists (select 1 from user where order.user_id = user.id and status=1);上面提到的这个场景其实使用 in 关键字去实现业务的话会更合适。为什么呢?因为如果 sql 语句中包含了 in 关键字,则它会优先执行in里面的 子查询语句,然后再执行in外面的语句。如果说in里面的数据量少,作为查询条件速度就会更快。而如果sql语句中包含了 exists 关键字,它会优先执行exists左边的语句(也就是主查询语句)。然后把它作为条件,去跟右边的语句匹配,如果匹配上了,就可以查询出数据,如果没有匹配上,数据就会被过滤掉。而在这个需求中 order表有10000条数据,user表只有100条数据。order表是大表,user表是小表。如果order表在左边,则用in关键字性能更好。总结:in 适合左边大表,右边小表exists 适合左边小表,右边大表无论是用 in 还是 exists 关键字,核心思想都是 小表驱动大表。4、批量操作如果你有一批数据经过业务处理之后,需要插入数据,该怎么办?反例:for(Order order : list){ orderMapper.insert(order); }在循环中逐条插入数据。insert into order(id,code,user_id) values(123,'001',100);该操作需要多次请求数据库,才能完成这批数据的插入。但是总所周知,在代码中每次远程请求数据库,都会有一定的性能消耗。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。那该如何优化?正例:orderMapper.insertBatch(list);提供一个批量插入数据的方法:insert into order(id,code,user_id) values(123,'001',100),(124,'002',100),(125,'001',101);这样做的话只会远程请求数据库一次,sql性能会有提升,数据量越多,性能提升越明显。但是需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。5、多用 limit有时需要查询某些数据中的第一条,比如:某个用户下的第一个订单,想看看他首单时间。反例:select id,create_date from order where user_id=123 order by create_date asc;根据用户id查询订单,按照下单时间排序,先查出该用户所有的订单数据,得到一个订单集合,然后在代码中获取第一个元素的数据,即首单的数据,然后就可以获取到首单时间。List<Order> list = orderMapper.getOrderList(); Order order = list.get(0);当你不知道怎么实现的时候,用这种方法为了现实功能是可以的,但是它效率不高,需要先查询出所有的数据,有点浪费资源。那么应该怎么优化?下面是正例:select id,create_date from order where user_id=123 order by create_date asc limit 1;使用 limit 1 , 只返回该用户下单时间最小的一条数据即可。另外,在删除或者修改数据时,为了防止误操作,导致删除或修改了不想干的数据,也可以在sql语句后面加上limit。例如:update order set status=0,edit_time=now(3) where id>=100 and id<200 limit 100;这样即使误操作,比如把id搞错了,也不会对太多的数据造成影响。6、in中值太多对于批量查询接口,我们通常会用 in 关键字过滤数据。比如:想通过指定的一些id批量查询出用户信息。sql语句如下:select id,name from category where id in (1,2,3...100000000);如果不做任何限制,该查询语句一次性可能会查出非常多的数据,很容易导致接口超时。这个时候该怎么呢?select id,name from category where id in (1,2,3...100000000) limit 500;也就是说可以在sql中对数据使用limit进行限制。不过我们更多的是要在业务代码中加限制,伪代码如下:public List<Category> getCategory(List<long> ids){ if((CollectionUtils.isEmpty(ids)){ return null; } if(ids.size() > 500){ throw new BusinessException("一次最多查询500条记录"); } return mapper.getCategoryList(ids); }还有一个方案就是:如果ids超过500条记录,可以分批用多线程去查询数据。每批只查询500条记录,最后把查询到的数据汇总到一起返回。不过这只是一个临时方案,不适合ids是在太多的场景。因为ids太多,即使能够快速查询出数据,但结果返回的数据量太大了,网络传输也是非常消耗性能的,接口性能始终好不到哪里。7、增量查询有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。反例:select * from user;如果直接获取所有的数据,然后同步过去。这样虽说非常方便,但是带来了一个非常大的问题,那就是如果数据很多的话,查询性能会非常差。这时该怎么办?正例:select * from user where id > #{lastId} and create_time >= #{lastCreateTime} limit 100;按id和时间升序,每次只同步一批数据,这一批数据只有100条记录。每次同步完成之后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用。最后通过这种增量查询的方式,能够提升单次查询的效率。8、高效分页有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。在mysql中分页一般用的 limit 关键字:select id,name,age from user limit 10,20;如果表中数据量少,用limit关键字做分页,没啥问题。但是如果表中数据量多,用它就会出现性能问题。比如现在分页参数变成了:select id,name,age from user limit 1000000,20;mysql会查到1000020条数据,然后丢弃前面的1000000条,只查后面的20条数据,这个是非常浪费资源的。那么,这种海量数据该怎么分页呢?优化sql:select id,name,age from user where id > 1000000 limit 20;先找到上次分页的最大id,然后利用id上的索引查询。不过该方案,要求uid是连续并且有序的。还能使用 betwwen 优化分页。select id,name,age from user where id between 1000000 and 1000020;需要注意的是between需要在唯一索引上分页,不然会出现每页大小不一致的问题。9、用连接查询代替子查询mysql中如果要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询子查询例子:select * from order where user_id in (select id from user where status=1);子查询语句可以通过 in 关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。(第3点小表驱动大表中有讲)子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。这时可以改成连接查询。具体例子如下:select o.* from order o inner join user u on o.user_id = u.id where u.status=1;10、join的表不宜过多根据阿里巴巴开发者手册的规定,join表的数量不应该超过3个。反例:select a.name,b.name.c.name,d.name from a inner join b on a.id = b.a_id inner join c on c.b_id = b.id inner join d on d.c_id = c.id inner join e on e.d_id = d.id inner join f on f.e_id = e.id inner join g on g.f_id = f.id如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。并且如果没有命中中,nested loop join 就是分别从两个表读一行数据进行两两对比,复杂度是 n^2。所以我们应该尽量控制join表的数量。正例:select a.name,b.name.c.name,a.d_name from a inner join b on a.id = b.a_id inner join c on c.b_id = b.id如果实现业务场景中需要查询出另外几张表中的数据,可以在a、b、c表中冗余专门的字段,比如:在表a中冗余d_name字段,保存需要查询出的数据。不过有些ERP系统,并发量不大,但业务比较复杂,需要join十几张表才能查询出数据。所以join表的数量要根据系统的实际情况决定,不能一概而论,尽量越少越好。11、join时要注意我们在涉及到多张表联合查询的时候,一般会使用join关键字。而join使用最多的是left join和inner join。left join : 求两个表的交集外加左表剩下的数据。inner join:求两个表交集的数据。使用 inner join 示例:select o.id,o.code,u.name from order o left join user u on o.user_id = u.id where u.status=1;如果两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。要特别注意的是在用 left join 关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。12、控制索引的数量众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。那么,问题来了,如果表中的索引太多,超过了5个该怎么办?这个问题要辩证的看,如果你的系统并发量不高,表中的数据量也不多,其实超过5个也可以,只要不要超过太多就行。但对于一些高并发的系统,请务必遵守单表索引数量不要超过5的限制。那么,高并发系统如何优化索引数量?能够建联合索引,就别建单个索引,可以删除无用的单个索引。将部分查询功能迁移到其他类型的数据库中,比如:Elastic Seach、HBase等,在业务表中只需要建几个关键索引即可。13、选择合理的字段类型char 表示固定字符串类型,该类型的字段存储空间是固定的,会浪费存储空间。alter table order add column code char(20) NOT NULL;varchar 表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间。alter table order add column code varchar(20) NOT NULL;如果是长度固定的字段,比如用户手机号,一般都是11位的,可以定义成char类型,长度是11字节。但如果是企业名称字段,假如定义成char类型,就有问题了。如果长度定义得太长,比如定义成了200字节,而实际企业长度只有50字节,则会浪费150字节的存储空间。如果长度定义得太短,比如定义成了50字节,但实际企业名称有100字节,就会存储不下,而抛出异常。所以建议将企业名称改成varchar类型,变长字段存储空间小,可以节省存储空间,而且对于查询来说,在一个相对较小的字段内搜索效率显然要高些。我们在选择字段类型时,应该遵循这样的原则:能用数字类型,就不用字符串,因为字符的处理往往比数字要慢尽可能使用小的类型,比如:用bit存布尔值,用tinyint存枚举值等长度固定的字符串字段,用char类型长度可变的字符串字段,用varchar类型金额字段用decimal,避免精度丢失问题。还有很多原则,这里不一一列举。14、提升group by的效率我们有很多业务场景需要使用 group by 关键字,它主要的功能是去重和分组。通常它会跟 having 一起配合使用,表示分组后再根据一定的条件过滤数据。反例:select user_id,user_name from order group by user_id having user_id <= 200;这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?select user_id,user_name from order where user_id <= 200 group by user_id;使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。其实这是一种思路,不仅限于group by的优化。我们的sql语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升sql整体的性能。15、索引优化sql优化当中,有一个非常重要的内容就是:索引优化。很多时候sql语句,走了索引,和没有走索引,执行效率差别很大。所以索引优化被作为sql优化的首选。索引优化的第一步是:检查sql语句有没有走索引。那么,如何查看sql走了索引没?可以使用 explain 命令,查看mysql的执行计划。例如:explain select * from 'order' where code='002';结果:通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:说实话,sql语句没有走索引,排除没有建索引之外,最大的可能性是索引失效了。下面说说索引失效的常见原因:如果不是上面的这些原因,则需要再进一步排查一下其他原因。
-
Mysql设置时区的多种解决方法 问题是这样来的,William导入一个项目后,连接局域网内另一台电脑的Mysql,死活连不上。控制台报错信息提示将Mysql连接驱动改为新的 com.mysql.cj.driver,但是改了之后没啥用,然后使用IDEA自带的连接Mysql试一下,就是页面右侧的Database,也是连接不上,有个提示说是返回的时区有问题,那就是因为mysql数据库时区问题导致无法连接呗。没改之前的报错信息:Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary. 2021-10-12 08:50:25.884 ERROR 43878 --- [ restartedMain] o.a.t.j.p.ConnectionPool : Unable to create initial connections of pool. java.sql.SQLNonTransientConnectionException: Could not create connection to database server. Attempted reconnect 3 times. Giving up.解决Mysql时区问题有好几个方法,William选择的是修改JDBC的连接,加了个时区设置 serverTimezone=Asia/Shanghai ,最后设置为:jdbc:mysql://localhost:3306/数据库名?serverTimezone=Asia/Shanghai&autoReconnect=true&useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false查Mysql的时区执行下面的代码可以进行查询select timediff(now(),convert_tz(now(),@@session.time_zone,'+00:00'));或者SELECT TIMEDIFF(NOW(), UTC_TIMESTAMP);或者show variables like '%time_zone%';如果是中国标准时间, 会输出 08:00动态修改时区set global time_zone = '+8:00'; ##修改mysql全局时区为北京时间,即我们所在的东8区 set time_zone = '+8:00'; ##修改当前会话时区 flush privileges; #立即生效在jdbc url指定默认时区还有一种是在jdbc连接的url后面加上 serverTimezone=UTC 或 GMT 即可,如果指定使用 gmt+8 时区,需要写成 GMT%2B8,否则可能报解析为空的错误。示例如下:jdbc:mysql://localhost:3306/demo?serverTimezone=UTC&characterEncoding=utf-8jdbc.url=jdbc:mysql://localhost:3306/demo?serverTimezone=GMT%2B8&characterEncoding=utf-8jdbc.url=jdbc:mysql://localhost:3306/demo?serverTimezone=Asia/Shanghai&characterEncoding=utf-8 就是增加了 serverTimezone=UTC serverTimezone=GMT%2B8更推荐使用 serverTimezone=Asia/Shanghai多余的话如果 pom.xml 中 mysql connector的版本没有切换到高版本,比如 8.0.16,就算在application.xml中修改了mysql的驱动为 com.mysql.cj.driver,控制台还是会有红色提示的,也是提示你Loading class 'com.mysql.jdbc.Driver'. This is deprecated. The new driver class is 'com.mysql.cj.jdbc.Driver'但这时候是不影响运行跟数据库连接的,有代码洁癖的可以修改一下。
-
Mysql5.7解决only_full_group_by错误 原因mysql5.7.x 版本,默认是开启了 only_full_group_by 模式的,而 only_full_group_by 模式下 SELECT 后面接的列必须被 GROUP BY 后面接的列所包含。也就是SQL语句应该是下面这样:SELECT id,name from table group by id,name,sex解决办法修改 mysql 配置文件,CentOS7 的 mysql 配置文件位置 /etc/my.cnf在 datadir = /data/mysql 下面添加一行:sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES保存退出,重启 mysqlsystemctl restart mysqld
-
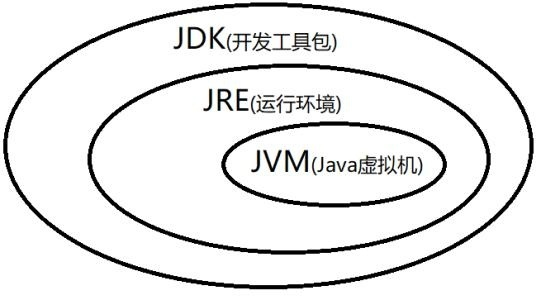
CentOS 7 部署环境安装 JDK+Nginx+MySQL+Redis+Tomcat+Docker 安装JDK下面两种方式都可以安装,第一个是安装JRE,另一个是安装JDK。JRE 和 JDK 有什么区别?JRE(Java Runtime Environment, Java运行环境)是提供给 Java 程序运行的最小环境,换句话说,没有 JRE,JDK 程序就无法运行。JDK(Java Development Kit,Java开发工具包)是提供给 Java 程序员的开发工具包,是整个 Java 开发的核心。换句话说,没有 JDK,Java 程序员就无法使用 Java 语言编写 Java 程序。也就是说,JDK 是用于开发 Java 程序的最小环境。JVM(Java Virtual Machine, Java虚拟机)是JRE的一部分。JVM主要工作是解释自己的指令集(即字节码)并映射到本地的CPU指令集和OS的系统调用。Java语言是跨平台运行的,不同的操作系统会有不同的JVM映射规则,使之与操作系统无关,完成跨平台性。1、安装 OpenJDK 8 JREsudo yum install java-1.8.0-openjdk2、安装 OpenJDK 8 JDKsudo yum install java-1.8.0-openjdk-devel验证是否安装成功java -version // 或 javac -version查看Java路径update-alternatives --config java把 Java 添加到环境变量中编辑 .bash_profile 文件vim .bash_profile将光标移到文件最后,按 a 输入,填写路径:export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export PATH=$JAVA_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar填写完,让修改生效source .bash_profile查看修改结果:echo $JAVA_HOME // 输出结果 /usr/lib/jvm/java-1.8.0-openjdk另一种方式,下载JDK手动安装下载JDK,上传到服务器或者服务器直接下载 jdk:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html mkdir /usr/local/java/ tar -zxvf jdk-8u291-linux-x64-demos.tar.gz -C /usr/local/java/ vi /etc/profile export JAVA_HOME=/usr/local/java/jdk-8u291 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=$PATH:${JAVA_HOME}/bin source /etc/profile安装 MySQL使用yum安装mysql5.7wget http://repo.mysql.com/mysql57-community-release-el7-11.noarch.rpm # mysql8 # wget http://repo.mysql.com/mysql80-community-release-el8-1.noarch.rpm rpm -ivh mysql57-community-release-el7-11.noarch.rpm #如果直接安装可能会报错,所以这一步看需要 yum module disable mysql # 安装mysql server yum -y install mysql-community-server # 启动mysql systemctl start mysqld.service # 查看mysql状态 systemctl status mysqld.service # 查看mysql初始密码 grep "password" /var/log/mysqld.log # 登录mysql mysql -u root -p # 更改密码,有字符要求 ALTER USER 'root'@'localhost' IDENTIFIED BY '新密码'; # 开启远程连接(通常不建议,因为不安全) GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION; # 刷新权限 flush privileges;安装Nginx安装编译环境sudo yum install -y gcc-c++ sudo yum install -y pcre pcre-devel sudo yum install -y zlib zlib-devel sudo yum install -y openssl openssl-devel添加Nginx仓库sudo yum install epel-release执行安装sudo yum install nginx启动Nginxsudo systemctl start nginx设置开机自启动sudo systemctl enable nginx安装Redis安装前更新软件源yum update -y下载Redis源码wget https://download.redis.io/releases/redis-6.2.5.tar.gz安装C++编译环境# 安装c++ yum install gcc-c++ -y # 查看版本 gcc -v编译安装tar -zxvf redis-6.2.5.tar.gz cd redis-6.2.5 make # 默认安装,通常这个就够了,安装在 /usr/local/bin make install # 自定义安装,PREFIX 是你想要安装的路径 # make install PREFIX=/usr/local/redis设置开机自启动# 进入到刚开始解压的redis-6.2.5目录中,把配置文件复制到安装目录中 cp redis.conf /usr/local/bin/ cd usr/local/bin # 编辑配置文件,把 daemonized 的值从 no 改为 yes,并保存,退出 vim redis.conf cd /etc/systemd/system # 创建自启动服务空白文件 touch redis.service编辑 redis.service,写入以下代码[Unit] #服务描述 Description=Redis Server Manager #服务类别 After=syslog.target network.target [Service] #后台运行的形式 Type=forking #服务命令。 路径根据自己实际情况填写,默认安装的话是下面这个路径 ExecStart=/usr/local/bin/redis-server /usr/local/bin/redis.conf #给服务分配独立的临时空间 PrivateTmp=true [Install] #运行级别下服务安装的相关设置,可设置为多用户,即系统运行级别为3 WantedBy=multi-user.target常用命令#启动redis服务 systemctl start redis.service #设置redis开机自启动 systemctl enable redis.service #停止redis开机自启动 systemctl disable redis.service #查看redis服务当前状态 systemctl status redis.service #重新启动redis服务 systemctl restart redis.service #查看所有已启动的服务 systemctl list-units --type=service(可选)开启远程连接firewall-cmd --zone=public --add-port=6379/tcp --permanent firewall-cmd --reload修改 redis.conf 配置文件关闭 protected-mode 模式,即将其值设置成 no, 此时外部网络可以直接访问将 bind 127.0.0.1 修改成 bind * -::* 。 或者直接将bind这一行注释掉设置密码,在 protected-mode yes 下面添加一行 requirepass password使用redis-cli连接其他服务器redis进入到 /usr/local/bin 目录,执行以下代码./redis-cli -h 你服务器的ip -p 6379 -a 你的密码安装Tomcat下载Tomcat安装包官方Tomcat8下载:https://tomcat.apache.org/download-80.cgi# 进入到你想安装的目录,比如 /usr/local/tomcat wget https://downloads.apache.org/tomcat/tomcat-8/v8.5.66/bin/apache-tomcat-8.5.66.tar.gz安装tar -zxvf apache-tomcat-8.5.47.tar.gz启动进入到tomcat目录,比如上面说的目录cd /usr/local/tomcat/apache-tomcat-8.5.47/bin ./startup.sh查看是否启动成功ps -ef | grep tomcat设置Tomcat开机自启动进入到 tomcat 的 bin 目录,就是启动那一步的 bin 目录,创建一个脚本 setenv.sh# 设置Tomcat的PID文件 CATALINA_PID="$CATALINA_BASE/tomcat.pid" # 添加JVM选项 JAVA_OPTS="-server -XX:PermSize=256M -XX:MaxPermSize=1024m -Xms512M -Xmx1024M -XX:MaxNewSize=256m"在/usr/local/tomcat/apache-tomcat-8.5.47/bin/catalina.sh文件开头添加JAVA_HOME和JRE_HOME,其中 /usr/lib/jvm/java-1.8.0-openjdk 为 jdk 的安装目录export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export JRE_HOME=/usr/lib/jvm/java-1.8.0-openjdk/jre如果在catalina.sh不配置JAVA_HOME和JRE_HOME就会报错误在 /usr/lib/systemd/system 路径下添加 tomcat.service 文件,内容如下:[Unit] Description=Tomcat After=network.target remote-fs.target nss-lookup.target [Service] Type=forking TimeoutSec=0 PIDFile=/usr/local/tomcat/apache-tomcat-8.5.47/tomcat.pid ExecStart=/usr/local/tomcat/apache-tomcat-8.5.47/bin/startup.sh ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s QUIT $MAINPID PrivateTmp=true [Install] WantedBy=multi-user.targetservice 文件修改后需要调用systemctl daemon-reload命令重新加载配置TimeoutSec=0的目的是让开机启动不处理tomcat启动超时,保证tomcat耗时过长时不会被系统terminating,如果不配置可能出现错误把Tomcat加入自启动列表systemctl enable tomcat.service安装Dockeryum install -y yum-utils device-mapper-persistent-dat yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum install docker-ce
-
解决Mysql主键自动增长删除后新增数据不连续 问题mysql表中删除自增id数据后,再添加数据时,id不会连续自增。比如原来有id:1 2 3 4 5 6,然后我们删除了5 和 6,下次新增是从7开始而不是5开始解决办法执行一下SQL语句:ALTER TABLE 表名 AUTO_INCREMENT =1;再一个,如果是从序号中间删除,那么即使是使用了上面的语句,一样是不能够连续的这时候需要先删除id列,然后重新添加先删除id列:alter table 表名 drop 列名;然后重新添加:alter table 表名 add 列名 int not null primary key auto increment first;
-
Docker实现容器数据持久化的两种方法 Bind volume 和 Volume Docker中的数据,比如Mysql,Redis这些,在容器重启或被删除以后,数据是不会保留的,也就是说数据没有持久化。在Docker中实现数据持久化有两种方式:Bind Mount:Bind mount 方式是 docker 早期使用的容器与宿主机数据共享的方式,可以实现将宿主机上的文件或目录挂载(mount)到 docker 容器中使用。相对于 volume 方式,bind mount 方式存在不少的局限。例如,bind mount 在 Linux 和 Windows 操作系统下不可移植。因此 docker 官方推荐使用 volume 方式。William在这里以Mysql镜像为例子,将/home/mysql目录挂载到容器的/var/lib/mysql目录中docker run --name mysql -it -p 3306:3306 -v /home/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql对于bind mount,有几点需要注意。-v 宿主机目录路径必须以 / 或 ~/ 开头,否则 docker 会将其当成是 volume 而不是 bind mount如果宿主机上的目录不存在,docker 会自动创建该目录如果容器中的目录不存在,docker 会自动创建该目录如果容器中的目录已有内容,那么 docker 会使用宿主机上目录的内容覆盖容器目录的内容Volume:与 bind mount 不同,volume 由 docker 创建和管理,docker 所有的 volume 都保存在宿主机文件系统的 /var/lib/docker/volumes 目录下(但是macOS 是以虚拟机形式运行 docker的,因此并不存在该目录,可以参考 stackoverflow)。Docker 引入 volume 的原因有:删除容器时,volume 不会被删除在不同的容器之间共享 volume (存储 / 数据)容器与存储分离将 volume 存储在远程主机或云上可以使用 docker run -v 参数为启动容器加载一个 volume,例如(最新版本镜像默认不用加tag,特定版本要加):docker run --name mysql_test -d -p 3306:3306 -v /data -e MYSQL_ROOT_PASSWORD=123456 mysql:tag这时候就启动了一个名为mysql_test的mysql容器,使用docker exec -it mysql_test bash进入到mysql_test容器中的data目录创建一个文件 touch test.txt 然后退出容器,使用inspect命令查看刚才容器启动时做了什么:docker inspect mysql_test可以看到一大串 JSON 格式的输出,我们重点关注 Mounts 字段的输出:"Mounts": [ { "Type": "volume", "Name": "57be41568e142560aaf333beb9a4dd7b79a37c78a45a4d930a31455f24fe7d13", "Source": "/var/lib/docker/volumes/57be41568e142560aaf333beb9a4dd7b79a37c78a45a4d930a31455f24fe7d13/_data", "Destination": "/data", "Driver": "local", "Mode": "", "RW": true, "Propagation": "" }, { "Type": "volume", "Name": "6d826d6b7b2c00d4f78cedadf997d393b51cb79b5a65b531372274c806efc3ce", "Source": "/var/lib/docker/volumes/6d826d6b7b2c00d4f78cedadf997d393b51cb79b5a65b531372274c806efc3ce/_data", "Destination": "/var/lib/mysql", "Driver": "local", "Mode": "", "RW": true, "Propagation": "" } ]可以看到,当容器 mysql_test 加载一个 volume (/data)时,docker 在目录 /var/lib/docker/volumes/ 创建一个新的目录,用来存储容器中产生的文件。同时,我们注意到 /data 的 RW 属性为 true,即可读可写。重新启动 container1 容器,再进入容器会发现刚才创建的test.txt还在,说明即使容器关闭,之前在 volume 存储的文件仍然会保留下来,即数据持久化没问题!先停掉容器docker stop mysql_test,再删掉容器 docker rm mysql_test,使用命令 docker volume ls可以看到,刚才的两个volume57be41568e142560aaf333beb9a4dd7b79a37c78a45a4d930a31455f24fe7d13 6d826d6b7b2c00d4f78cedadf997d393b51cb79b5a65b531372274c806efc3ce仍然存在。也就是说,即使容器不存在了,volume 仍可在宿主机上保存下来。如果需要在其他容器也使用这个 volume,可以使用以下命令加载指定的 volume:docker run -it -v 57be41568e142560aaf333beb9a4dd7b79a37c78a45a4d930a31455f24fe7d13:/data container_name挂载指定的 volume上面的 docker run -v 命令中,我们并没有指定 volume 的名称,这样 docker 会默认给我们创建一个匿名的 volume,就是很长的那字符串。我们也可以挂载指定名称的 volume:docker run -it -v my-volume:/data --name 自定义容器名 镜像名:tag这样,我们在启动容器该容器时,将挂载一个名为 my-volume 的 volume,并挂载到容器的 /data 目录。对于 docker 来说,如果 my-volume 不存在,那么 docker 就会自动创建该 volume,并挂载到 /data 目录。比如运行的是Reids:docker run -d -it -v redis_volume:/data --name myRedis redis执行 docker volume inspect redis_volume 查看redis挂载的volume信息可以看到 my-volume 的 JSON 输出信息:[ { "CreatedAt": "2020-08-24T09:33:30-04:00", "Driver": "local", "Labels": null, "Mountpoint": "/var/lib/docker/volumes/redis_volume/_data", "Name": "redis_volume", "Options": null, "Scope": "local" } ]可以看到redis_volume的宿主机目录位置是:/var/lib/docker/volumes/redis_volume/_data除了让 docker 帮我们自动创建 volume,我们也可以自行创建 volume:docker volume create my-volume删除volume命令是:docker volume rm volume-name然后将这个手工创建的 volume 挂载到容器:docker run -d -v redis_volume2:/data --name myRedis001 redis
-
解决连接Docker中的Mysql速度慢问题 问题描述:由于MySQL是使用Docker容器搭建起来的,William在数据库连接中,发现比平时的连接速度变慢了不少,每次连接大概延迟了10秒左右。排查过程1、 服务器资源查看系统的CPU、网络等负载,无异常。2、数据库连接池检查是否连接数过多导致,登入MySQL后kill掉一部分连接,发现还是连接缓慢。3.、网络问题在ping服务器的时候并没有出现数据包延迟、丢包现象。网络问题排除。4、DNS解析问题修改MySQL配置文件,添加skip-name-resolve:先进入到Mysql容器中:docker exec -it container-name bash编辑Mysql配置文件: vim /etc/mysql/my.cnf 在文件的[mysqld]这一部分的最后添加skip-name-resolve如下所示:[mysqld] pid-file = /var/run/mysqld/mysqld.pid socket = /var/run/mysqld/mysqld.sock datadir = /var/lib/mysql secure-file-priv= NULL skip-name-resolve5、推出容器,重启mysql容器:docker restart container-id