搜索到
40
篇与
的结果
-
 Java8+使用 Stream 玩转集合的筛选、归约、分组、聚合 Stream的使用Stream有两种操作,一个是中间操作,每次返回一个新的流,可以有多个;另一个是终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值stream不同于java.io的InputStream和OutputStream,它代表的是任意Java对象的序列。两者对比如下: java.iojava.util.stream存储顺序读写的 byte 或 char顺序输出任意java对象实例用途序列化至文件或网络内存计算、业务逻辑Stream和List也不一样,List存储的每个元素都是已经存储在内存中的某个Java对象,而Stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。 java.util.listjava.util.stream元素已分配并存储在内存可能未分配,实时计算用途操作一组已存在的Java对象惰性计算Stream的特点:它可以“存储”有限个或无限个元素。这里的存储打了个引号,是因为元素有可能已经全部存储在内存中,也有可能是根据需要实时计算出来的。Stream的另一个特点是,一个Stream可以轻易地转换为另一个Stream,而不是修改原Stream本身。最后,真正的计算通常发生在最后结果的获取,也就是惰性计算。惰性计算的特点是:一个Stream转换为另一个Stream时,实际上只存储了转换规则,并没有任何计算发生。1、创建StreamStream.of创建Stream最简单的方式是直接用Stream.of()静态方法,传入可变参数即创建了一个能输出确定元素的Stream:public class Main { public static void main(String[] args) { Stream<String> stream = Stream.of("A", "B", "C", "D"); // forEach()方法相当于内部循环调用, // 可传入符合Consumer接口的void accept(T t)的方法引用: stream.forEach(System.out::println); } }基于数组或Collection第二种创建Stream的方法是基于一个数组或者Collection,这样该Stream输出的元素就是数组或者Collection持有的元素:public class Main { public static void main(String[] args) { Stream<String> stream1 = Arrays.stream(new String[] { "A", "B", "C" }); Stream<String> stream2 = List.of("X", "Y", "Z").stream(); stream1.forEach(System.out::println); stream2.forEach(System.out::println); } }把数组变成Stream使用Arrays.stream()方法。对于Collection(List、Set、Queue等),直接调用stream()方法就可以获得Stream。基于Supplier创建Stream还可以通过Stream.generate()方法,它需要传入一个Supplier对象:Stream<String> s = Stream.generate(Supplier<String> sp);基于Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。public class Main { public static void main(String[] args) { Stream<Integer> natual = Stream.generate(new NatualSupplier()); // 注意:无限序列必须先变成有限序列再打印: natual.limit(20).forEach(System.out::println); } } class NatualSupplier implements Supplier<Integer> { int n = 0; public Integer get() { n++; return n; } }对于无限序列,如果直接调用forEach()或者count()这些最终求值操作,会进入死循环,因为永远无法计算完这个序列,所以正确的方法是先把无限序列变成有限序列,例如,用limit()方法可以截取前面若干个元素,这样就变成了一个有限序列,对这个有限序列调用forEach()或者count()操作就没有问题。其他方法创建Stream的第三种方法是通过一些API提供的接口,直接获得Stream。例如,Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容:try (Stream<String> lines = Files.lines(Paths.get("/path/to/file.txt"))) { ... }Java的范型不支持基本类型,所以我们无法用Stream<int>这样的类型,会发生编译错误。为了提高效率,Java标准库提供了IntStream、LongStream和DoubleStream这三种使用基本类型的Stream,它们的使用方法和范型Stream没有大的区别,设计这三个Stream的目的是提高运行效率:// 将int[]数组变为IntStream: IntStream is = Arrays.stream(new int[] { 1, 2, 3 }); // 将Stream<String>转换为LongStream: LongStream ls = List.of("1", "2", "3").stream().mapToLong(Long::parseLong);小结创建Stream的方法有 :通过指定元素、指定数组、指定Collection创建Stream;通过Supplier创建Stream,可以是无限序列;通过其他类的相关方法创建。基本类型的Stream有IntStream、LongStream和DoubleStream。2、使用mapStream.map()是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream。所谓map操作,就是把一种操作运算,映射到一个序列的每一个元素上。例如,对x计算它的平方,可以使用函数f(x) = x * x。我们把这个函数映射到一个序列1,2,3,4,5上,就得到了另一个序列1,4,9,16,25: f(x) = x * x │ │ ┌───┬───┬───┬───┼───┬───┬───┬───┐ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 2 3 4 5 6 7 8 9 ] │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 4 9 16 25 36 49 64 81 ]可见,map操作,把一个Stream的每个元素一一对应到应用了目标函数的结果上。JDK9 在 List、Set、Map 等,都提供了 of()方法,表面上看來,它们似乎只是建立 List、Set、Map 实例的便捷方法利用map(),不但能完成数学计算,对于字符串操作,以及任何Java对象都是非常有用的。例如:public class Main { public static void main(String[] args) { List.of(" Apple ", " pear ", " ORANGE", " BaNaNa ") .stream() .map(String::trim) // 去空格 .map(String::toLowerCase) // 变小写 .forEach(System.out::println); // 打印 } } // 输出 apple pear orange banana3、使用 filterStream.filter()是Stream的另一个常用转换方法。所谓filter()操作,就是对一个Stream的所有元素一一进行测试,不满足条件的就被“滤掉”了,剩下的满足条件的元素就构成了一个新的Stream。例如,我们对1,2,3,4,5这个Stream调用filter(),传入的测试函数f(x) = x % 2 != 0用来判断元素是否是奇数,这样就过滤掉偶数,只剩下奇数,因此我们得到了另一个序列1,3,5: f(x) = x % 2 != 0 │ │ ┌───┬───┬───┬───┼───┬───┬───┬───┐ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 2 3 4 5 6 7 8 9 ] │ X │ X │ X │ X │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ [ 1 3 5 7 9 ]用IntStream写出上述逻辑,代码如下:public class Main { public static void main(String[] args) { IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9) .filter(n -> n % 2 != 0) .forEach(System.out::println); } }4、使用reducemap()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果。 可见,reduce()操作首先初始化结果为指定值(这里是0),紧接着,reduce()对每个元素依次调用(acc, n) -> acc + n,其中,acc是上次计算的结果:import java.util.stream.*; public class Main { public static void main(String[] args) { int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (acc, n) -> acc + n); System.out.println(sum); // 45 } }// 计算过程: acc = 0 // 初始化为指定值 acc = acc + n = 0 + 1 = 1 // n = 1 acc = acc + n = 1 + 2 = 3 // n = 2 acc = acc + n = 3 + 3 = 6 // n = 3 acc = acc + n = 6 + 4 = 10 // n = 4 acc = acc + n = 10 + 5 = 15 // n = 5 acc = acc + n = 15 + 6 = 21 // n = 6 acc = acc + n = 21 + 7 = 28 // n = 7 acc = acc + n = 28 + 8 = 36 // n = 8 acc = acc + n = 36 + 9 = 45 // n = 9利用reduce(),我们可以把求和改成求积,计算求积时,初始值必须设置为1,代码也十分简单:int s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(1, (acc, n) -> acc * n);5、输出集合Stream的几个常见操作:map()、filter()、reduce()。这些操作对Stream来说可以分为两类,一类是转换操作,即把一个Stream转换为另一个Stream,例如map()和filter(),另一类是聚合操作,即对Stream的每个元素进行计算,得到一个确定的结果,例如reduce()。对于Stream来说,对其进行转换操作并不会触发任何计算!输出为Listcollect(Collectors.toList())可以把Stream的每个元素收集到List中Stream<String> stream = Stream.of("Apple", "", null, "Pear", " ", "Orange"); List<String> list = stream.filter(s -> s != null && !s.isBlank()).collect(Collectors.toList()); System.out.println(list);collect(Collectors.toSet())可以把Stream的每个元素收集到Set中输出为数组只需要调用toArray()方法,并传入数组的“构造方法”:List<String> list = List.of("Apple", "Banana", "Orange"); String[] array = list.stream().toArray(String[]::new);collect(Collectors.toSet())可以把Stream的每个元素收集到Set中输出为Map要把Stream的元素收集到Map中,就稍微麻烦一点。因为对于每个元素,添加到Map时需要key和value,因此,我们要指定两个映射函数,分别把元素映射为key和value:public class Main { public static void main(String[] args) { Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft"); Map<String, String> map = stream .collect(Collectors.toMap( // 把元素s映射为key: s -> s.substring(0, s.indexOf(':')), // 把元素s映射为value: s -> s.substring(s.indexOf(':') + 1))); System.out.println(map); } }分组输出分组输出使用 Collectors.groupingBy(),它需要提供两个函数:一个是分组的key,这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组,第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List,上述代码运行结果如下:public class Main { public static void main(String[] args) { List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots"); Map<String, List<String>> groups = list.stream() .collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList())); System.out.println(groups); } }输出{ A=[Apple, Avocado, Apricots], B=[Banana, Blackberry], C=[Coconut, Cherry] }6、其他操作排序对Stream的元素进行排序十分简单,只需调用sorted()方法:public class Main { public static void main(String[] args) { List<String> list = List.of("Orange", "apple", "Banana") .stream() .sorted() .collect(Collectors.toList()); System.out.println(list); } }去重对一个Stream的元素进行去重,没必要先转换为Set,可以直接用distinct():List.of("A", "B", "A", "C", "B", "D") .stream() .distinct() .collect(Collectors.toList()); // [A, B, C, D] 截取截取操作常用于把一个无限的Stream转换成有限的Stream,skip()用于跳过当前Stream的前N个元素,limit()用于截取当前Stream最多前N个元素:List.of("A", "B", "C", "D", "E", "F") .stream() .skip(2) // 跳过A, B .limit(3) // 截取C, D, E .collect(Collectors.toList()); // [C, D, E]合并将两个Stream合并为一个Stream可以使用Stream的静态方法concat():Stream<String> s1 = List.of("A", "B", "C").stream(); Stream<String> s2 = List.of("D", "E").stream(); // 合并: Stream<String> s = Stream.concat(s1, s2); System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]flatMap如果Stream的元素的合集是:Stream<List<Integer>> s = Stream.of( Arrays.asList(1, 2, 3), Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9));而我们希望把上述Stream转换为Stream<Integer>,就可以使用flatMap():Stream<Integer> i = s.flatMap(list -> list.stream());因此,所谓flatMap(),是指把Stream的每个元素(这里是List)映射为Stream,然后合并成一个新的Stream:┌─────────────┬─────────────┬─────────────┐ │┌───┬───┬───┐│┌───┬───┬───┐│┌───┬───┬───┐│ ││ 1 │ 2 │ 3 │││ 4 │ 5 │ 6 │││ 7 │ 8 │ 9 ││ │└───┴───┴───┘│└───┴───┴───┘│└───┴───┴───┘│ └─────────────┴─────────────┴─────────────┘ │ │flatMap(List -> Stream) │ │ ▼ ┌───┬───┬───┬───┬───┬───┬───┬───┬───┐ │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ 9 │ └───┴───┴───┴───┴───┴───┴───┴───┴───┘并行通常情况下,对Stream的元素进行处理是单线程的,即一个一个元素进行处理。但是很多时候,我们希望可以并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。把一个普通Stream转换为可以并行处理的Stream非常简单,只需要用parallel()进行转换:Stream<String> s = ... String[] result = s.parallel() // 变成一个可以并行处理的Stream .sorted() // 可以进行并行排序 .toArray(String[]::new);经过parallel()转换后的Stream只要可能,就会对后续操作进行并行处理。我们不需要编写任何多线程代码就可以享受到并行处理带来的执行效率的提升。分组// 将员工按薪资是否高于8000分组 Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000)); // 将员工按性别分组 Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex)); // 将员工先按性别分组,再按地区分组 Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));接合joining 可以将 stream 中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。List<String> list = Arrays.asList("A", "B", "C"); String string = list.stream().collect(Collectors.joining("-")); // 拼接后的字符串:A-B-C排序sorted,中间操作。有两种排序:sorted():自然排序,流中元素需实现 Comparable 接口sorted(Comparator com):Comparator 排序器自定义排序// 按工资升序排序(自然排序) List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName) .collect(Collectors.toList()); // 按工资倒序排序 List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()) .map(Person::getName).collect(Collectors.toList()); // 先按工资再按年龄升序排序 List<String> newList3 = personList.stream() .sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName) .collect(Collectors.toList()); // 先按工资再按年龄自定义排序(降序) List<String> newList4 = personList.stream().sorted((p1, p2) -> { if (p1.getSalary() == p2.getSalary()) { return p2.getAge() - p1.getAge(); } else { return p2.getSalary() - p1.getSalary(); } }).map(Person::getName).collect(Collectors.toList());总结Stream提供的常用操作有:转换操作:map(),filter(),sorted(),distinct();合并操作:concat(),flatMap();并行处理:parallel();聚合操作:reduce(),collect(),count(),max(),min(),sum(),average();其他操作:allMatch(), anyMatch(), forEach()。
Java8+使用 Stream 玩转集合的筛选、归约、分组、聚合 Stream的使用Stream有两种操作,一个是中间操作,每次返回一个新的流,可以有多个;另一个是终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值stream不同于java.io的InputStream和OutputStream,它代表的是任意Java对象的序列。两者对比如下: java.iojava.util.stream存储顺序读写的 byte 或 char顺序输出任意java对象实例用途序列化至文件或网络内存计算、业务逻辑Stream和List也不一样,List存储的每个元素都是已经存储在内存中的某个Java对象,而Stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。 java.util.listjava.util.stream元素已分配并存储在内存可能未分配,实时计算用途操作一组已存在的Java对象惰性计算Stream的特点:它可以“存储”有限个或无限个元素。这里的存储打了个引号,是因为元素有可能已经全部存储在内存中,也有可能是根据需要实时计算出来的。Stream的另一个特点是,一个Stream可以轻易地转换为另一个Stream,而不是修改原Stream本身。最后,真正的计算通常发生在最后结果的获取,也就是惰性计算。惰性计算的特点是:一个Stream转换为另一个Stream时,实际上只存储了转换规则,并没有任何计算发生。1、创建StreamStream.of创建Stream最简单的方式是直接用Stream.of()静态方法,传入可变参数即创建了一个能输出确定元素的Stream:public class Main { public static void main(String[] args) { Stream<String> stream = Stream.of("A", "B", "C", "D"); // forEach()方法相当于内部循环调用, // 可传入符合Consumer接口的void accept(T t)的方法引用: stream.forEach(System.out::println); } }基于数组或Collection第二种创建Stream的方法是基于一个数组或者Collection,这样该Stream输出的元素就是数组或者Collection持有的元素:public class Main { public static void main(String[] args) { Stream<String> stream1 = Arrays.stream(new String[] { "A", "B", "C" }); Stream<String> stream2 = List.of("X", "Y", "Z").stream(); stream1.forEach(System.out::println); stream2.forEach(System.out::println); } }把数组变成Stream使用Arrays.stream()方法。对于Collection(List、Set、Queue等),直接调用stream()方法就可以获得Stream。基于Supplier创建Stream还可以通过Stream.generate()方法,它需要传入一个Supplier对象:Stream<String> s = Stream.generate(Supplier<String> sp);基于Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。public class Main { public static void main(String[] args) { Stream<Integer> natual = Stream.generate(new NatualSupplier()); // 注意:无限序列必须先变成有限序列再打印: natual.limit(20).forEach(System.out::println); } } class NatualSupplier implements Supplier<Integer> { int n = 0; public Integer get() { n++; return n; } }对于无限序列,如果直接调用forEach()或者count()这些最终求值操作,会进入死循环,因为永远无法计算完这个序列,所以正确的方法是先把无限序列变成有限序列,例如,用limit()方法可以截取前面若干个元素,这样就变成了一个有限序列,对这个有限序列调用forEach()或者count()操作就没有问题。其他方法创建Stream的第三种方法是通过一些API提供的接口,直接获得Stream。例如,Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容:try (Stream<String> lines = Files.lines(Paths.get("/path/to/file.txt"))) { ... }Java的范型不支持基本类型,所以我们无法用Stream<int>这样的类型,会发生编译错误。为了提高效率,Java标准库提供了IntStream、LongStream和DoubleStream这三种使用基本类型的Stream,它们的使用方法和范型Stream没有大的区别,设计这三个Stream的目的是提高运行效率:// 将int[]数组变为IntStream: IntStream is = Arrays.stream(new int[] { 1, 2, 3 }); // 将Stream<String>转换为LongStream: LongStream ls = List.of("1", "2", "3").stream().mapToLong(Long::parseLong);小结创建Stream的方法有 :通过指定元素、指定数组、指定Collection创建Stream;通过Supplier创建Stream,可以是无限序列;通过其他类的相关方法创建。基本类型的Stream有IntStream、LongStream和DoubleStream。2、使用mapStream.map()是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream。所谓map操作,就是把一种操作运算,映射到一个序列的每一个元素上。例如,对x计算它的平方,可以使用函数f(x) = x * x。我们把这个函数映射到一个序列1,2,3,4,5上,就得到了另一个序列1,4,9,16,25: f(x) = x * x │ │ ┌───┬───┬───┬───┼───┬───┬───┬───┐ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 2 3 4 5 6 7 8 9 ] │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 4 9 16 25 36 49 64 81 ]可见,map操作,把一个Stream的每个元素一一对应到应用了目标函数的结果上。JDK9 在 List、Set、Map 等,都提供了 of()方法,表面上看來,它们似乎只是建立 List、Set、Map 实例的便捷方法利用map(),不但能完成数学计算,对于字符串操作,以及任何Java对象都是非常有用的。例如:public class Main { public static void main(String[] args) { List.of(" Apple ", " pear ", " ORANGE", " BaNaNa ") .stream() .map(String::trim) // 去空格 .map(String::toLowerCase) // 变小写 .forEach(System.out::println); // 打印 } } // 输出 apple pear orange banana3、使用 filterStream.filter()是Stream的另一个常用转换方法。所谓filter()操作,就是对一个Stream的所有元素一一进行测试,不满足条件的就被“滤掉”了,剩下的满足条件的元素就构成了一个新的Stream。例如,我们对1,2,3,4,5这个Stream调用filter(),传入的测试函数f(x) = x % 2 != 0用来判断元素是否是奇数,这样就过滤掉偶数,只剩下奇数,因此我们得到了另一个序列1,3,5: f(x) = x % 2 != 0 │ │ ┌───┬───┬───┬───┼───┬───┬───┬───┐ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 2 3 4 5 6 7 8 9 ] │ X │ X │ X │ X │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ [ 1 3 5 7 9 ]用IntStream写出上述逻辑,代码如下:public class Main { public static void main(String[] args) { IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9) .filter(n -> n % 2 != 0) .forEach(System.out::println); } }4、使用reducemap()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果。 可见,reduce()操作首先初始化结果为指定值(这里是0),紧接着,reduce()对每个元素依次调用(acc, n) -> acc + n,其中,acc是上次计算的结果:import java.util.stream.*; public class Main { public static void main(String[] args) { int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (acc, n) -> acc + n); System.out.println(sum); // 45 } }// 计算过程: acc = 0 // 初始化为指定值 acc = acc + n = 0 + 1 = 1 // n = 1 acc = acc + n = 1 + 2 = 3 // n = 2 acc = acc + n = 3 + 3 = 6 // n = 3 acc = acc + n = 6 + 4 = 10 // n = 4 acc = acc + n = 10 + 5 = 15 // n = 5 acc = acc + n = 15 + 6 = 21 // n = 6 acc = acc + n = 21 + 7 = 28 // n = 7 acc = acc + n = 28 + 8 = 36 // n = 8 acc = acc + n = 36 + 9 = 45 // n = 9利用reduce(),我们可以把求和改成求积,计算求积时,初始值必须设置为1,代码也十分简单:int s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(1, (acc, n) -> acc * n);5、输出集合Stream的几个常见操作:map()、filter()、reduce()。这些操作对Stream来说可以分为两类,一类是转换操作,即把一个Stream转换为另一个Stream,例如map()和filter(),另一类是聚合操作,即对Stream的每个元素进行计算,得到一个确定的结果,例如reduce()。对于Stream来说,对其进行转换操作并不会触发任何计算!输出为Listcollect(Collectors.toList())可以把Stream的每个元素收集到List中Stream<String> stream = Stream.of("Apple", "", null, "Pear", " ", "Orange"); List<String> list = stream.filter(s -> s != null && !s.isBlank()).collect(Collectors.toList()); System.out.println(list);collect(Collectors.toSet())可以把Stream的每个元素收集到Set中输出为数组只需要调用toArray()方法,并传入数组的“构造方法”:List<String> list = List.of("Apple", "Banana", "Orange"); String[] array = list.stream().toArray(String[]::new);collect(Collectors.toSet())可以把Stream的每个元素收集到Set中输出为Map要把Stream的元素收集到Map中,就稍微麻烦一点。因为对于每个元素,添加到Map时需要key和value,因此,我们要指定两个映射函数,分别把元素映射为key和value:public class Main { public static void main(String[] args) { Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft"); Map<String, String> map = stream .collect(Collectors.toMap( // 把元素s映射为key: s -> s.substring(0, s.indexOf(':')), // 把元素s映射为value: s -> s.substring(s.indexOf(':') + 1))); System.out.println(map); } }分组输出分组输出使用 Collectors.groupingBy(),它需要提供两个函数:一个是分组的key,这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组,第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List,上述代码运行结果如下:public class Main { public static void main(String[] args) { List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots"); Map<String, List<String>> groups = list.stream() .collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList())); System.out.println(groups); } }输出{ A=[Apple, Avocado, Apricots], B=[Banana, Blackberry], C=[Coconut, Cherry] }6、其他操作排序对Stream的元素进行排序十分简单,只需调用sorted()方法:public class Main { public static void main(String[] args) { List<String> list = List.of("Orange", "apple", "Banana") .stream() .sorted() .collect(Collectors.toList()); System.out.println(list); } }去重对一个Stream的元素进行去重,没必要先转换为Set,可以直接用distinct():List.of("A", "B", "A", "C", "B", "D") .stream() .distinct() .collect(Collectors.toList()); // [A, B, C, D] 截取截取操作常用于把一个无限的Stream转换成有限的Stream,skip()用于跳过当前Stream的前N个元素,limit()用于截取当前Stream最多前N个元素:List.of("A", "B", "C", "D", "E", "F") .stream() .skip(2) // 跳过A, B .limit(3) // 截取C, D, E .collect(Collectors.toList()); // [C, D, E]合并将两个Stream合并为一个Stream可以使用Stream的静态方法concat():Stream<String> s1 = List.of("A", "B", "C").stream(); Stream<String> s2 = List.of("D", "E").stream(); // 合并: Stream<String> s = Stream.concat(s1, s2); System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]flatMap如果Stream的元素的合集是:Stream<List<Integer>> s = Stream.of( Arrays.asList(1, 2, 3), Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9));而我们希望把上述Stream转换为Stream<Integer>,就可以使用flatMap():Stream<Integer> i = s.flatMap(list -> list.stream());因此,所谓flatMap(),是指把Stream的每个元素(这里是List)映射为Stream,然后合并成一个新的Stream:┌─────────────┬─────────────┬─────────────┐ │┌───┬───┬───┐│┌───┬───┬───┐│┌───┬───┬───┐│ ││ 1 │ 2 │ 3 │││ 4 │ 5 │ 6 │││ 7 │ 8 │ 9 ││ │└───┴───┴───┘│└───┴───┴───┘│└───┴───┴───┘│ └─────────────┴─────────────┴─────────────┘ │ │flatMap(List -> Stream) │ │ ▼ ┌───┬───┬───┬───┬───┬───┬───┬───┬───┐ │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ 9 │ └───┴───┴───┴───┴───┴───┴───┴───┴───┘并行通常情况下,对Stream的元素进行处理是单线程的,即一个一个元素进行处理。但是很多时候,我们希望可以并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。把一个普通Stream转换为可以并行处理的Stream非常简单,只需要用parallel()进行转换:Stream<String> s = ... String[] result = s.parallel() // 变成一个可以并行处理的Stream .sorted() // 可以进行并行排序 .toArray(String[]::new);经过parallel()转换后的Stream只要可能,就会对后续操作进行并行处理。我们不需要编写任何多线程代码就可以享受到并行处理带来的执行效率的提升。分组// 将员工按薪资是否高于8000分组 Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000)); // 将员工按性别分组 Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex)); // 将员工先按性别分组,再按地区分组 Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));接合joining 可以将 stream 中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。List<String> list = Arrays.asList("A", "B", "C"); String string = list.stream().collect(Collectors.joining("-")); // 拼接后的字符串:A-B-C排序sorted,中间操作。有两种排序:sorted():自然排序,流中元素需实现 Comparable 接口sorted(Comparator com):Comparator 排序器自定义排序// 按工资升序排序(自然排序) List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName) .collect(Collectors.toList()); // 按工资倒序排序 List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()) .map(Person::getName).collect(Collectors.toList()); // 先按工资再按年龄升序排序 List<String> newList3 = personList.stream() .sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName) .collect(Collectors.toList()); // 先按工资再按年龄自定义排序(降序) List<String> newList4 = personList.stream().sorted((p1, p2) -> { if (p1.getSalary() == p2.getSalary()) { return p2.getAge() - p1.getAge(); } else { return p2.getSalary() - p1.getSalary(); } }).map(Person::getName).collect(Collectors.toList());总结Stream提供的常用操作有:转换操作:map(),filter(),sorted(),distinct();合并操作:concat(),flatMap();并行处理:parallel();聚合操作:reduce(),collect(),count(),max(),min(),sum(),average();其他操作:allMatch(), anyMatch(), forEach()。 -
Java8关于日期的处理方法 获取今天的日期Java 8 中的 LocalDate 用于表示当天日期。和 java.util.Date 不同,它只有日期,不包含时间。当你仅需要表示日期时就用这个类。LocalDate today = LocalDate.now(); System.out.println("今天的日期: " + today); // 输出:今天的日期: 2021-10-13获取年、月、日信息LocalDate now = LocalDate.now(); int year = now.getYear(); int month = now.getMonthValue(); int day = now.getDayOfMonth(); System.out.println("year:" + year); System.out.println("month:" + month); System.out.println("day:" + day); // 输出 // year:2021 // month:10 // day:13处理特定日期我们通过静态工厂方法 now() 非常容易地创建了当天日期,你还可以调用另一个有用的工厂方法 LocalDate.of() 创建任意日期, 该方法需要传入年、月、日做参数,返回对应的LocalDate实例。这个方法的好处是没再犯老API的设计错误,比如年度起始于1900,月份是从0开 始等等。LocalDate date = LocalDate.of(2018,2,6); System.out.println("自定义日期:"+date); // 输出 自定义日期:2018-02-06获取当前时间,不含日期LocalTime time = LocalTime.now(); System.out.println("获取当前的时间,不含有日期:" + time); // 输出:获取当前的时间,不含有日期:16:33:06.914现在时间进行加减未来时间:plusHours, plusMinutes, plusSeconds。分别是加小时,加分钟,加秒过去时间:plus替换成minus。对应减操作LocalTime time = LocalTime.now(); LocalTime newTime = time.plusHours(3); System.out.println("现在的时间:" + time); System.out.println("三个小时后的时间为:" + newTime); // 输出: // 现在的时间:16:43:42.642 // 三个小时后的时间为: 19:43:42.642计算一周后的日期和上个例子计算3小时以后的时间类似,这个例子会计算一周后的日期。LocalDate日期不包含时间信息,它的plus()方法用来增加天、周、月,ChronoUnit类声明了这些时间单位。由于LocalDate也是不变类型,返回后一定要用变量赋值。LocalDate today = LocalDate.now(); System.out.println("今天的日期为:" + today); LocalDate nextWeek = today.plus(1, ChronoUnit.WEEKS); System.out.println("一周后的日期为:" + nextWeek); // 输出 // 今天的日期为:2021-10-13 // 一周后的日期为:2021-10-20可以看到新日期离当天日期是7天,也就是一周。你可以用同样的方法增加1个月、1年、1小时、1分钟甚至一个世纪,ChronoUnit后的WEEKS,换成YEARS,MONTHS,HOURS,MINUTES,DAYS。那要是想计算,减操作呢?就把 today.plus 改成 today.minus判断日期是早于还是晚于另一个日期LocalDate类有两类方法 isBefore() 和 isAfter() 用于比较日期。调用isBefore()方法时,如果给定日期小于当前日期则返回true。LocalDate today = LocalDate.now(); LocalDate tomorrow = LocalDate.of(2021, 12, 6); if (tomorrow.isAfter(today)) { System.out.println("之后的日期:" + tomorrow); } LocalDate yesterday = today.minus(1, ChronoUnit.DAYS); if (yesterday.isBefore(today)) { System.out.println("之前的日期:" + yesterday); } // 输出 // 之后的日期:2021-12-06 // 之前的日期:2021-10-12字符串互转日期类型LocalDateTime date = LocalDateTime.now(); DateTimeFormatter format1 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); //日期转字符串 String str = date.format(format1); System.out.println("日期转换为字符串:" + str); DateTimeFormatter format2 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); //字符串转日期 LocalDate date2 = LocalDate.parse(str, format2); System.out.println("日期类型:" + date2); // 输出 // 日期转换为字符串:2021-10-13 17:28:51 // 日期类型:2021-10-13
-
Mysql设置时区的多种解决方法 问题是这样来的,William导入一个项目后,连接局域网内另一台电脑的Mysql,死活连不上。控制台报错信息提示将Mysql连接驱动改为新的 com.mysql.cj.driver,但是改了之后没啥用,然后使用IDEA自带的连接Mysql试一下,就是页面右侧的Database,也是连接不上,有个提示说是返回的时区有问题,那就是因为mysql数据库时区问题导致无法连接呗。没改之前的报错信息:Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary. 2021-10-12 08:50:25.884 ERROR 43878 --- [ restartedMain] o.a.t.j.p.ConnectionPool : Unable to create initial connections of pool. java.sql.SQLNonTransientConnectionException: Could not create connection to database server. Attempted reconnect 3 times. Giving up.解决Mysql时区问题有好几个方法,William选择的是修改JDBC的连接,加了个时区设置 serverTimezone=Asia/Shanghai ,最后设置为:jdbc:mysql://localhost:3306/数据库名?serverTimezone=Asia/Shanghai&autoReconnect=true&useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false查Mysql的时区执行下面的代码可以进行查询select timediff(now(),convert_tz(now(),@@session.time_zone,'+00:00'));或者SELECT TIMEDIFF(NOW(), UTC_TIMESTAMP);或者show variables like '%time_zone%';如果是中国标准时间, 会输出 08:00动态修改时区set global time_zone = '+8:00'; ##修改mysql全局时区为北京时间,即我们所在的东8区 set time_zone = '+8:00'; ##修改当前会话时区 flush privileges; #立即生效在jdbc url指定默认时区还有一种是在jdbc连接的url后面加上 serverTimezone=UTC 或 GMT 即可,如果指定使用 gmt+8 时区,需要写成 GMT%2B8,否则可能报解析为空的错误。示例如下:jdbc:mysql://localhost:3306/demo?serverTimezone=UTC&characterEncoding=utf-8jdbc.url=jdbc:mysql://localhost:3306/demo?serverTimezone=GMT%2B8&characterEncoding=utf-8jdbc.url=jdbc:mysql://localhost:3306/demo?serverTimezone=Asia/Shanghai&characterEncoding=utf-8 就是增加了 serverTimezone=UTC serverTimezone=GMT%2B8更推荐使用 serverTimezone=Asia/Shanghai多余的话如果 pom.xml 中 mysql connector的版本没有切换到高版本,比如 8.0.16,就算在application.xml中修改了mysql的驱动为 com.mysql.cj.driver,控制台还是会有红色提示的,也是提示你Loading class 'com.mysql.jdbc.Driver'. This is deprecated. The new driver class is 'com.mysql.cj.jdbc.Driver'但这时候是不影响运行跟数据库连接的,有代码洁癖的可以修改一下。
-
IDEA设置默认换行符 这应该不算什么大问题,只是刚好遇到,因为William原本想着自己的一台Macbook Air这边写代码,另一台Windows也能写,所以就两台操作同一个Github Repo了。在Macbook上写完后,commit的时候IDEA弹出一个提示,大概就是:you are about to commit CRLF什么鬼的。谷歌搜了一下说是windows跟linux,mac的末尾换行符不一致。windows默认是CRLF,而linux和macOS是LF,代码不做任何转换提交的话,后面编译估计会出现问题。怎么设置默认为LF,让windows和MacBook同步呢?第一步左上角IDEA图标进入 Preferences,或者快捷键command加英文状态逗号 command ,第二步点击 Editor --> Code Style,进来后可以看到默认是 System-Dependent,中文是根据系统自动配置,如果你是windows系统,默认是CRLF,服务器是Linux,你就得自己换了。 保存后,下次创建文件就默认是 LF 格式换行符了。另外其实也可以在创建文件以后,右下角点击 CRLF 或者 LF 进行切换。只不过这样麻烦一点,没创建一个都需要进行设置。
-
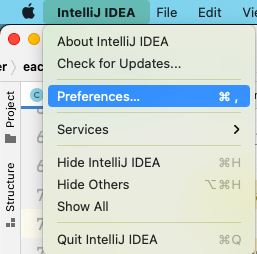
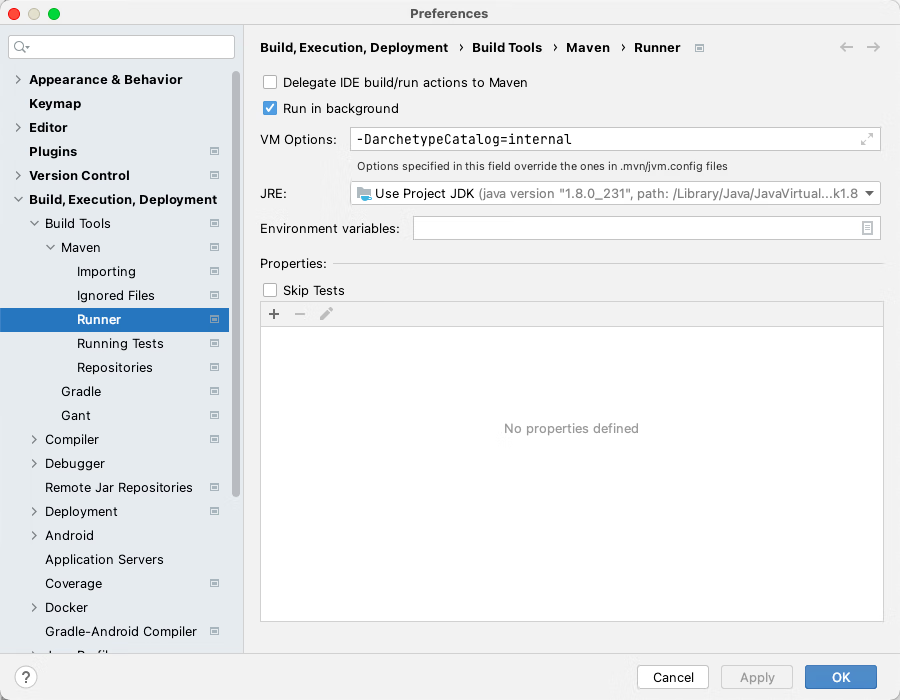
Maven IDEA设置优先从本地仓库查找获取依赖 如果不设置 Maven 优先从本地仓库获取依赖的话,那么当你关闭项目以后,下次再打开,IDEA又跑到网上去查找以来,即使制定了使用阿里云的仓库,比起本地速度还是比较慢的。所以很有必要设置为优先使用本地仓库已有的依赖。Macbook上点击左上角IDEA的图标,选择 Preferences,再点击 Build, Execution, Deployment >> Build Tool >> Maven >> Runner >> VM Options 中填入 -DarchetypeCatalog=internal附带阿里云 maven 仓库镜像打开 maven 的配置文件( windows 机器一般在 maven 安装目录的 conf/settings.xml ),在标签中添加 mirror 子节点:<mirror> <id>aliyunmaven</id> <mirrorOf>*</mirrorOf> <name>阿里云公共仓库</name> <url>https://maven.aliyun.com/repository/public</url> </mirror>
-
Java调用SSL异常,报错javax.net.ssl.SSLHandshakeException 问题场景因为业务需要,服务器迁移,重新部署环境过程中出现部分接口错误,后来发现是 jdk1.8 版本导致 SSL 调用权限上有问题。报如下错误:Caused by: javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate)解决方案修改 java 安装目录中,lib 下的 security 文件。比如路径是:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64/jre/lib/security搜索SSLv3,将 SSLv3,TLSv1, TLSv1.1 三个都删掉,有些可能没有后两个,那就只删除 SSLv3。保存退出,然后重启自己的项目就可以了
-
Java集合框架 List,Set,Map三者的区别List :(对付顺序的好帮手)存储的元素是有序的,可重复的。Set :(注重独一无二的性质)存储的元素是无序的,不可重复的Map :(用key搜索的专家)使用键值对(key-value)存储,key是无序的、不可重复的、value是无序的、可重复的,每个键最多映射到一个值。如何选用集合?主要根据集合的特点来选,比如需要根据键值获取元素的值,就选用 Map 接口下的集合,需要排序就选 TreeMap,不需要排序就选 HashMap,要保证线程安全就选用 ConcurrentHashMap如果只是需要存放元素,那么可以选择实现 collection 接口的集合,需要保证元素唯一性时选择 Set 接口的集合比如 TreeSet或HashSet。不需要就选择实现 List 接口的比如 ArrayList 或 LinkedList,然后再根据实现这些接口的集合的特点进行选择。为什么要选用集合?当我们需要保存一组类型相同的数据的时候,我们应该用一个容器来保存,这个容器就是数组,但是,使用数组来存放对象有一定的弊端,因为在实际开发中,存储的数据的类型是多样的,于是,就出现了集合。集合也是用来存放多个数据的。数组的缺点是一旦声明了以后,长度就不可变了;同时,声明数组时确定的数据类型也决定了它存放的数据的数据类型;而且,数组存储的数据时有序的,可重复的,特点单一。但是集合提高了数据存储的灵活性,Java结合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据。Arraylist与Vector的区别?Arraylist 是 List 的主要实现类,底层使用的是 Object[ ] 存储,适用于频繁的查找工作,线程不安全。Vector 是 List 的古老实现类,底层使用的是 Object[ ] 存储,线程是安全的 。Arraylist 与 LinkedList 区别?是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;关于底层数据结构:Arraylist 底层使用的是 Object 数组,Linkedlist 底层使用的是双向链表(jdk1.6之前是循环,jdk1.7后取消了)插入和删除是否受元素位置影响Arraylist 采用数组存储,所以插入和删除元素的时间复杂度都会收到元素位置的影响。比如,增加的时候 ArrayList 是默认加到列表尾部的,那这时候复杂度就是 O(1)。但如果是要在指定位置i进行插入或删除的话,那么时间复杂度就是O(n-i)。因为上述两个操作集合中的第i个和第i个元素之后的 (n-i) 个元素都要执行向后/向前移动一位的操作。LinkedList采用链表存储,所以,如果是在头部插入或者删除元素不受元素位置的影响,近似O(1),如果是在指定位置 i 插入和删除元素的话,时间复杂度近似 O(n),因为需要先移动到指定位置再插入。是否支持快速随机访问:LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于 get(int index) 方法)内存空间占用:ArrayList的空间浪费主要体现在list列表在结尾会预留一定的容量空间,而 Linkedlist 的空间花费主要体现在每个元素都要消耗比 Arraylist 更多的空间(因为要存放直接后继,直接前驱及数据)comparable 和 Comparator 的区别comparable 接口实际上是出自 java.lang 包 它有一个 compareTo(Object obj)方法用来排序comparator接口实际上是出自 java.util 包它有一个 compare(Object obj1, Object obj2) 方法用来排序无序性和不可重复性的含义是什么1、什么是无序性?无序性不等于随机性 ,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。2、什么是不可重复性?不可重复性是指添加的元素按照 equals()判断时 ,返回 false,需要同时重写 equals()方法和 HashCode()方法。将数组转换为ArrayListJava8的Stream方法(推荐)Integer[] myarray = {1,2,3}; List myList = Arrays.stream(myarray).collect(Collectors.toList()); // 基本类型也可以实现转换(依赖boxed的装箱操作) int[] myarray2 = {1,2,3} List myList = Arrays.stream(myarray2).boxed().collect(Collectors.toList());
-