搜索到
144
篇与
的结果
-
 阿里云网盘实现webdav挂载,变身文件服务器 实现了阿里云盘的webdav协议,只需要简单的配置一下,就可以让阿里云盘变身为webdav协议的文件服务器。 基于此,你可以把阿里云盘挂载为Windows、Linux、Mac系统的磁盘,可以通过NAS系统做文件管理或文件同步使用方式Jar包William 是比较建议自己下载源码编译的,这样可以获取最新源码。这里也附上 William 在 2021-12-24 编译打包的文件:{cloud title="阿里云Webdav 2.4.0" type="lz" url="https://iyume.lanzouo.com/idBUBxxa5ri" password=""/}把 jar 包上传到服务器,执行下列命令即可运行java -jar webdav.jar --aliyundrive.refresh-token="your refreshToken"设置Jar包开机自启动隐藏内容,请前往内页查看详情Dockerdocker run -d --name=webdav-aliyundriver --restart=always -p 8080:8080 -v /etc/localtime:/etc/localtime -v /etc/aliyun-driver/:/etc/aliyun-driver/ -e TZ="Asia/Shanghai" -e ALIYUNDRIVE_REFRESH_TOKEN="你的refresh_token" -e ALIYUNDRIVE_AUTH_PASSWORD="admin" -e JAVA_OPTS="-Xmx1g" zx5253/webdav-aliyundriver # /etc/aliyun-driver/ 挂载卷自动维护了最新的refreshToken,建议挂载 # ALIYUNDRIVE_AUTH_PASSWORD 是admin账户的密码,建议修改 # JAVA_OPTS 可修改最大内存占用,比如 -e JAVA_OPTS="-Xmx512m" 表示最大内存限制为512mDocker-Composeversion: "3.0" services: webdav-aliyundriver: image: zx5253/webdav-aliyundriver container_name: aliyundriver environment: - TZ=Asia/Shanghai - ALIYUNDRIVE_REFRESH_TOKEN=refresh_token - ALIYUNDRIVE_AUTH_USER_NAME=admin - ALIYUNDRIVE_AUTH_PASSWORD=admin - JAVA_OPTS=-Xmx1g volumes: - /etc/aliyun-driver/:/etc/aliyun-driver/ ports: - 6666:8080 restart: always # “refreshToken”请根据下文说明自行获取。 # “ALIYUNDRIVE_AUTH_USER-NAME”和“ALIYUNDRIVE_AUTH_PASSWORD”为连接用户名和密码,建议更改。 # “/etc/aliyun-driver/:/etc/aliyun-driver/”,可以把冒号前改为指定目录,比如“/homes/USER/docker/alidriver/:/etc/aliyun-driver/”。 # 删除了“/etc/localtime:/etc/localtime”,如有需要同步时间请自行添加在environment下。 # 端口6666可自行按需更改,此端口为WebDAV连接端口,8080为容器内配置端口,修改请量力而为。 # 建议不要保留这些中文注释,以防报错,比如QNAP。参数说明--aliyundrive.refresh-token 阿里云盘的refreshToken,获取方式见下文 --server.port 非必填,服务器端口号,默认为8080 --aliyundrive.auth.enable=true 是否开启WebDav账户验证,默认开启 --aliyundrive.auth.user-name=admin WebDav账户,默认admin --aliyundrive.auth.password=admin WebDav密码,默认admin --aliyundrive.work-dir=/etc/aliyun-driver/ token挂载路径(如果多开的话,需修改此配置)refreshToken获取方式隐藏内容,请前往内页查看详情
阿里云网盘实现webdav挂载,变身文件服务器 实现了阿里云盘的webdav协议,只需要简单的配置一下,就可以让阿里云盘变身为webdav协议的文件服务器。 基于此,你可以把阿里云盘挂载为Windows、Linux、Mac系统的磁盘,可以通过NAS系统做文件管理或文件同步使用方式Jar包William 是比较建议自己下载源码编译的,这样可以获取最新源码。这里也附上 William 在 2021-12-24 编译打包的文件:{cloud title="阿里云Webdav 2.4.0" type="lz" url="https://iyume.lanzouo.com/idBUBxxa5ri" password=""/}把 jar 包上传到服务器,执行下列命令即可运行java -jar webdav.jar --aliyundrive.refresh-token="your refreshToken"设置Jar包开机自启动隐藏内容,请前往内页查看详情Dockerdocker run -d --name=webdav-aliyundriver --restart=always -p 8080:8080 -v /etc/localtime:/etc/localtime -v /etc/aliyun-driver/:/etc/aliyun-driver/ -e TZ="Asia/Shanghai" -e ALIYUNDRIVE_REFRESH_TOKEN="你的refresh_token" -e ALIYUNDRIVE_AUTH_PASSWORD="admin" -e JAVA_OPTS="-Xmx1g" zx5253/webdav-aliyundriver # /etc/aliyun-driver/ 挂载卷自动维护了最新的refreshToken,建议挂载 # ALIYUNDRIVE_AUTH_PASSWORD 是admin账户的密码,建议修改 # JAVA_OPTS 可修改最大内存占用,比如 -e JAVA_OPTS="-Xmx512m" 表示最大内存限制为512mDocker-Composeversion: "3.0" services: webdav-aliyundriver: image: zx5253/webdav-aliyundriver container_name: aliyundriver environment: - TZ=Asia/Shanghai - ALIYUNDRIVE_REFRESH_TOKEN=refresh_token - ALIYUNDRIVE_AUTH_USER_NAME=admin - ALIYUNDRIVE_AUTH_PASSWORD=admin - JAVA_OPTS=-Xmx1g volumes: - /etc/aliyun-driver/:/etc/aliyun-driver/ ports: - 6666:8080 restart: always # “refreshToken”请根据下文说明自行获取。 # “ALIYUNDRIVE_AUTH_USER-NAME”和“ALIYUNDRIVE_AUTH_PASSWORD”为连接用户名和密码,建议更改。 # “/etc/aliyun-driver/:/etc/aliyun-driver/”,可以把冒号前改为指定目录,比如“/homes/USER/docker/alidriver/:/etc/aliyun-driver/”。 # 删除了“/etc/localtime:/etc/localtime”,如有需要同步时间请自行添加在environment下。 # 端口6666可自行按需更改,此端口为WebDAV连接端口,8080为容器内配置端口,修改请量力而为。 # 建议不要保留这些中文注释,以防报错,比如QNAP。参数说明--aliyundrive.refresh-token 阿里云盘的refreshToken,获取方式见下文 --server.port 非必填,服务器端口号,默认为8080 --aliyundrive.auth.enable=true 是否开启WebDav账户验证,默认开启 --aliyundrive.auth.user-name=admin WebDav账户,默认admin --aliyundrive.auth.password=admin WebDav密码,默认admin --aliyundrive.work-dir=/etc/aliyun-driver/ token挂载路径(如果多开的话,需修改此配置)refreshToken获取方式隐藏内容,请前往内页查看详情 -
Debian11使用开机自启动脚本 因为搞阿里云盘的 webdav,用的是 Java 环境,最后想让 jar 包开机自启动,但是因为是 Debian11,进去 etc 目录发现没有 rc.local文件。反倒有好几个 rcx.local。在低版本的debian系linux系统中,增加开机自启脚本比较简单,直接修改 /etc/rc.local 文件,在 exit 0 之前增加需要运行的脚本即可。但是现在在高版本的linux中默认没有开启该功能,接下来我们通过设置来开启该功能。1、首先,我们到 /lib/systemd/system 目录下cd /lib/systemd/system2、在该目录下,可以发现有个 rc-local.service 文件,使用文本编辑器,在最后加上下列信息即可。隐藏内容,请前往内页查看详情3、由于没有 /etc/rc.local 文件,所以我们需要手动创建它,并写入以下信息#!/bin/sh -e # 在这里输入需要自启的脚本 exit 04、创建完成后需要给其赋予运行权限chmod +x /etc/rc.local5、启动该服务sudo systemctl enable rc-local # 启用 sudo systemctl start rc-local.service # 开始运行 sudo systemctl status rc-local.service # 查看状态这个时候,我们的开机自启服务就完成了。
-
-
linux突然所有命令都失效了,显示bash: xxxxx: command not found 今天登陆了一台日本的服务器配置OCI的,然后修改了下 /etc/profile 文件,由地方弄错了,然后就出现了,输入什么命令都是 command not found。想要重启 reboot 不行,ls 也不行。出现这个问题是因为系统的环境变量没有正确配置造成的,造成这个原因有很多,比如系统升级,比如不正当操作。解决的方式有两种。1、直接在linux命令行界面输入如下,然后回车(导入环境变量,以及shell常见的命令的存放地址):export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin2、如果系统所有命令都不能使用时,还可以使用绝对命令vi打开profile,想William这情况的话,把刚才改了的有问题的地方全删了就可以了。(其实,如果这里有问题的地方没删除或者说没有改成正确的话,即使用了第一种方法,等会你退出登陆以后,再进来还是那种not found的情况的,所以说这里一定是要改的)/bin/vi /etc/profile在系统的配置文件里添加环境变量地址export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
-
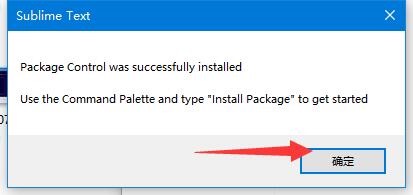
Sublime Text 4 正式版发布,附激活与汉化教程 版本特点:许可证更改:Sublime Text License 密钥(注册码)不再与独立的主要版本绑定,而是对购买后 3 年内的所有更新均有效,不过使用更新的版本需要升级 License。支持多 tab 选项卡:方便分割视图,支持通过界面或内置命令行使用。支持 Apple Silicon 和 Linux ARM64:Sublime Text for Mac 包含对 Apple Silicon 处理器的原生支持,Linux ARM64 builds 在树莓派等设备中可用。全新的 UI 界面语境感知自动补全:该版本重写了自动补全引擎,使之能够基于项目中的已有代码提供智能补全。支持 TypeScript、JSX 和 TSX语法定义升级:语法高亮引擎全新升级,能够处理非确定性语法、多行语句、lazy embed 和语法继承。此外,内存使用降低,加载速度更快。GPU 渲染:Sublime Text 4 稳定版在渲染界面时,能够在 Linux、Mac 和 Windows 系统中利用 GPU,从而带来流畅的 UI 界面,分辨率最高可达 8K,且消耗的能源更少。Python API 升级:Sublime Text 新版本 API 升级至 Python 3.8,同时具备对 Sublime Text 3 软件包的向后兼容性。Python API 新增了许多特性,如允许 LSP 等插件更好地运行。兼容性:Sublime Text 4 完全兼容 Sublime Text 3,可以自动接收旧版本的会话和配置。Sublime Text 还支持 3、4 版本的分开运行。软件下载官网下载地址:https://www.sublimetext.com/download软件汉化1、点击 Tools—Install Package Control,(安装包控件比较慢,并且没有反应,等待数分钟后会有弹窗)2、点击确定按钮3、菜单点击 Preferences – Package Control,选择 Install Package4、输入 ChineseLocalzations 可见中文包!选中即可安装!5、汉化成功激活软件目前来说windows上可以自行激活,但是macOS的话William尚未找到自行破解方法。都是下载的TNT的破解版。总之能不用破解版就不用破解版吧!1、在软件的安装目录找到 sublime_text.exe 文件。2、点击此处 进入在线十六进制编辑器,打开 sublime_text.exe 文件。3、然后查找以下字节并且替换(不同的软件版本替换的内容略有不同,一定要看好软件版本)。2021年11月1日 最新版本 Sublime Text 4 Build 4121,按步骤操作!第一步:X64版本4157415656575553B828210000 替换为 33C0FEC0C3575553B828210000X86版本55535756B8AC200000 替换为 33C0FEC0C3AC200000第二步:6C6963656E73652E7375626C696D6568712E636F6D 替换为 7375626C696D6568712E6C6F63616C686F73740000第三步:先点击左侧任意数字,然后粘贴要搜索的字节,再点击替换!最后左上角的另存为并替换旧的 sublime_text.exe 文件即可!(最好保存一下原文件)其他版本Sublime Text 4 Build 4113 依此替换下方 2 组字节!C3 C6 01 00 C3 替换为 C3 C6 01 01 C351 31 C0 88 05 替换为 51 b0 01 88 05Sublime Text 4 Build 4107 替换下方 1 组字节!80 38 00 74 2C 49 替换为 FE 00 90 74 2C 49第四步:替换exe后用以下注册码激活----- BEGIN LICENSE ----- IYUME.TOP Unlimited User License EA7E-81044230 0C0CD4A8 CAA317D9 CCABD1AC 434C984C 7E4A0B13 77893C3E DD0A5BA1 B2EB721C 4BAAB4C4 9B96437D 14EB743E 7DB55D9C 7CA26EE2 67C3B4EC 29B2C65A 88D90C59 CB6CCBA5 7DE6177B C02C2826 8C9A21B0 6AB1A5B6 20B09EA2 01C979BD 29670B19 92DC6D90 6E365849 4AB84739 5B4C3EA1 048CC1D0 9748ED54 CAC9D585 90CAD815 ------ END LICENSE ------激活成功的 about 页面
-
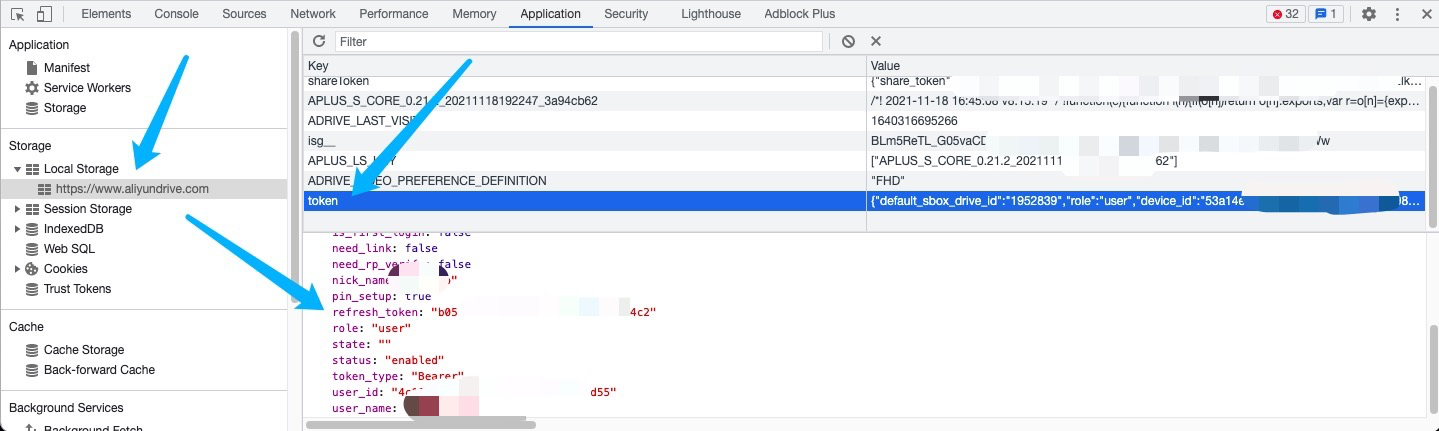
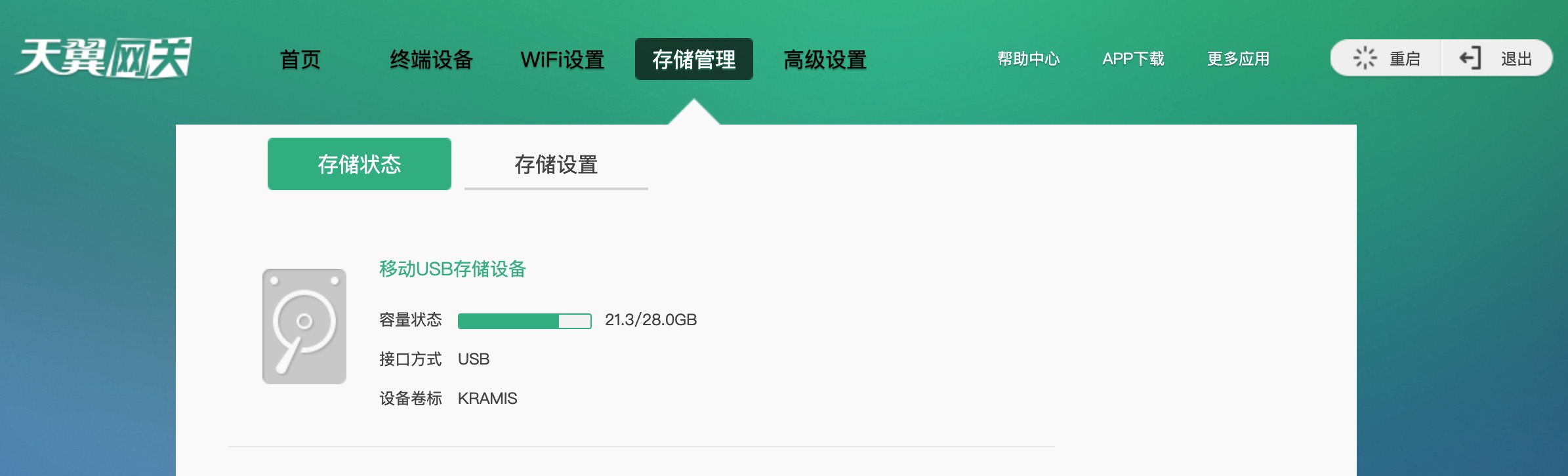
天翼网关PT926E获取超级管理员账号 登录管理面板,在光猫上插入U盘 在光猫中存储管理中进入U盘进入U盘内目录列表后,直接打开“浏览器开发者工具”,随便找一个文件夹。 例如我这里选中“DSMU”这个文件夹元素,右键Edit as HTML: 将四处 DSMU 修改为 .. (英文状态下的两个句号),然后点击..文件夹 就会进入上一级 再次用上一步的方式修改 usb1_2 为 .. ,就会进入路由器根目录 然后我们进入 /var/configl 将 lastgood.xml 文件复制到U盘中,即可取下U盘 将U盘,插入你的电脑中,打开 lastgood.xml ,搜索 SUSER_PASSWORD 即为超级管理员密码,SUSER_NAME为超级管理员用户名,使用该账号登录即可进入超级后台,然后该干嘛干嘛。 改桥接:
-
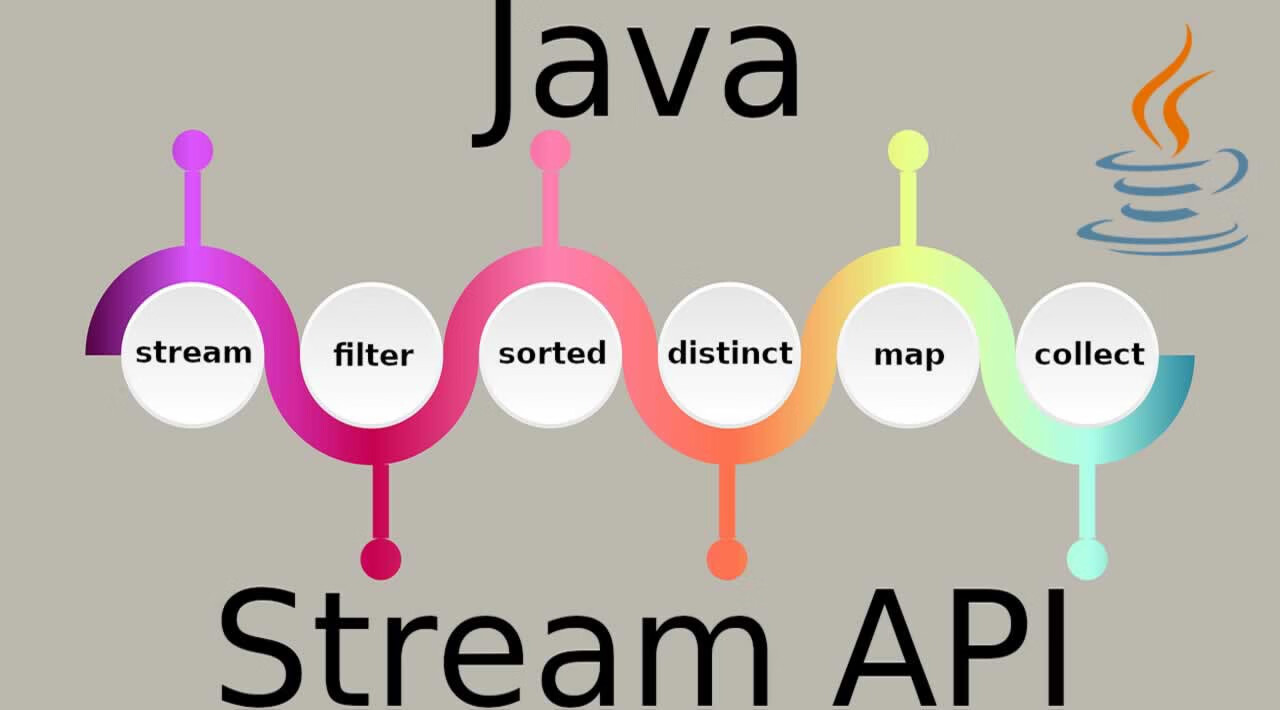
Java8+使用 Stream 玩转集合的筛选、归约、分组、聚合 Stream的使用Stream有两种操作,一个是中间操作,每次返回一个新的流,可以有多个;另一个是终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值stream不同于java.io的InputStream和OutputStream,它代表的是任意Java对象的序列。两者对比如下: java.iojava.util.stream存储顺序读写的 byte 或 char顺序输出任意java对象实例用途序列化至文件或网络内存计算、业务逻辑Stream和List也不一样,List存储的每个元素都是已经存储在内存中的某个Java对象,而Stream输出的元素可能并没有预先存储在内存中,而是实时计算出来的。 java.util.listjava.util.stream元素已分配并存储在内存可能未分配,实时计算用途操作一组已存在的Java对象惰性计算Stream的特点:它可以“存储”有限个或无限个元素。这里的存储打了个引号,是因为元素有可能已经全部存储在内存中,也有可能是根据需要实时计算出来的。Stream的另一个特点是,一个Stream可以轻易地转换为另一个Stream,而不是修改原Stream本身。最后,真正的计算通常发生在最后结果的获取,也就是惰性计算。惰性计算的特点是:一个Stream转换为另一个Stream时,实际上只存储了转换规则,并没有任何计算发生。1、创建StreamStream.of创建Stream最简单的方式是直接用Stream.of()静态方法,传入可变参数即创建了一个能输出确定元素的Stream:public class Main { public static void main(String[] args) { Stream<String> stream = Stream.of("A", "B", "C", "D"); // forEach()方法相当于内部循环调用, // 可传入符合Consumer接口的void accept(T t)的方法引用: stream.forEach(System.out::println); } }基于数组或Collection第二种创建Stream的方法是基于一个数组或者Collection,这样该Stream输出的元素就是数组或者Collection持有的元素:public class Main { public static void main(String[] args) { Stream<String> stream1 = Arrays.stream(new String[] { "A", "B", "C" }); Stream<String> stream2 = List.of("X", "Y", "Z").stream(); stream1.forEach(System.out::println); stream2.forEach(System.out::println); } }把数组变成Stream使用Arrays.stream()方法。对于Collection(List、Set、Queue等),直接调用stream()方法就可以获得Stream。基于Supplier创建Stream还可以通过Stream.generate()方法,它需要传入一个Supplier对象:Stream<String> s = Stream.generate(Supplier<String> sp);基于Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。public class Main { public static void main(String[] args) { Stream<Integer> natual = Stream.generate(new NatualSupplier()); // 注意:无限序列必须先变成有限序列再打印: natual.limit(20).forEach(System.out::println); } } class NatualSupplier implements Supplier<Integer> { int n = 0; public Integer get() { n++; return n; } }对于无限序列,如果直接调用forEach()或者count()这些最终求值操作,会进入死循环,因为永远无法计算完这个序列,所以正确的方法是先把无限序列变成有限序列,例如,用limit()方法可以截取前面若干个元素,这样就变成了一个有限序列,对这个有限序列调用forEach()或者count()操作就没有问题。其他方法创建Stream的第三种方法是通过一些API提供的接口,直接获得Stream。例如,Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容:try (Stream<String> lines = Files.lines(Paths.get("/path/to/file.txt"))) { ... }Java的范型不支持基本类型,所以我们无法用Stream<int>这样的类型,会发生编译错误。为了提高效率,Java标准库提供了IntStream、LongStream和DoubleStream这三种使用基本类型的Stream,它们的使用方法和范型Stream没有大的区别,设计这三个Stream的目的是提高运行效率:// 将int[]数组变为IntStream: IntStream is = Arrays.stream(new int[] { 1, 2, 3 }); // 将Stream<String>转换为LongStream: LongStream ls = List.of("1", "2", "3").stream().mapToLong(Long::parseLong);小结创建Stream的方法有 :通过指定元素、指定数组、指定Collection创建Stream;通过Supplier创建Stream,可以是无限序列;通过其他类的相关方法创建。基本类型的Stream有IntStream、LongStream和DoubleStream。2、使用mapStream.map()是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream。所谓map操作,就是把一种操作运算,映射到一个序列的每一个元素上。例如,对x计算它的平方,可以使用函数f(x) = x * x。我们把这个函数映射到一个序列1,2,3,4,5上,就得到了另一个序列1,4,9,16,25: f(x) = x * x │ │ ┌───┬───┬───┬───┼───┬───┬───┬───┐ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 2 3 4 5 6 7 8 9 ] │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 4 9 16 25 36 49 64 81 ]可见,map操作,把一个Stream的每个元素一一对应到应用了目标函数的结果上。JDK9 在 List、Set、Map 等,都提供了 of()方法,表面上看來,它们似乎只是建立 List、Set、Map 实例的便捷方法利用map(),不但能完成数学计算,对于字符串操作,以及任何Java对象都是非常有用的。例如:public class Main { public static void main(String[] args) { List.of(" Apple ", " pear ", " ORANGE", " BaNaNa ") .stream() .map(String::trim) // 去空格 .map(String::toLowerCase) // 变小写 .forEach(System.out::println); // 打印 } } // 输出 apple pear orange banana3、使用 filterStream.filter()是Stream的另一个常用转换方法。所谓filter()操作,就是对一个Stream的所有元素一一进行测试,不满足条件的就被“滤掉”了,剩下的满足条件的元素就构成了一个新的Stream。例如,我们对1,2,3,4,5这个Stream调用filter(),传入的测试函数f(x) = x % 2 != 0用来判断元素是否是奇数,这样就过滤掉偶数,只剩下奇数,因此我们得到了另一个序列1,3,5: f(x) = x % 2 != 0 │ │ ┌───┬───┬───┬───┼───┬───┬───┬───┐ │ │ │ │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ ▼ [ 1 2 3 4 5 6 7 8 9 ] │ X │ X │ X │ X │ │ │ │ │ │ ▼ ▼ ▼ ▼ ▼ [ 1 3 5 7 9 ]用IntStream写出上述逻辑,代码如下:public class Main { public static void main(String[] args) { IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9) .filter(n -> n % 2 != 0) .forEach(System.out::println); } }4、使用reducemap()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果。 可见,reduce()操作首先初始化结果为指定值(这里是0),紧接着,reduce()对每个元素依次调用(acc, n) -> acc + n,其中,acc是上次计算的结果:import java.util.stream.*; public class Main { public static void main(String[] args) { int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (acc, n) -> acc + n); System.out.println(sum); // 45 } }// 计算过程: acc = 0 // 初始化为指定值 acc = acc + n = 0 + 1 = 1 // n = 1 acc = acc + n = 1 + 2 = 3 // n = 2 acc = acc + n = 3 + 3 = 6 // n = 3 acc = acc + n = 6 + 4 = 10 // n = 4 acc = acc + n = 10 + 5 = 15 // n = 5 acc = acc + n = 15 + 6 = 21 // n = 6 acc = acc + n = 21 + 7 = 28 // n = 7 acc = acc + n = 28 + 8 = 36 // n = 8 acc = acc + n = 36 + 9 = 45 // n = 9利用reduce(),我们可以把求和改成求积,计算求积时,初始值必须设置为1,代码也十分简单:int s = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(1, (acc, n) -> acc * n);5、输出集合Stream的几个常见操作:map()、filter()、reduce()。这些操作对Stream来说可以分为两类,一类是转换操作,即把一个Stream转换为另一个Stream,例如map()和filter(),另一类是聚合操作,即对Stream的每个元素进行计算,得到一个确定的结果,例如reduce()。对于Stream来说,对其进行转换操作并不会触发任何计算!输出为Listcollect(Collectors.toList())可以把Stream的每个元素收集到List中Stream<String> stream = Stream.of("Apple", "", null, "Pear", " ", "Orange"); List<String> list = stream.filter(s -> s != null && !s.isBlank()).collect(Collectors.toList()); System.out.println(list);collect(Collectors.toSet())可以把Stream的每个元素收集到Set中输出为数组只需要调用toArray()方法,并传入数组的“构造方法”:List<String> list = List.of("Apple", "Banana", "Orange"); String[] array = list.stream().toArray(String[]::new);collect(Collectors.toSet())可以把Stream的每个元素收集到Set中输出为Map要把Stream的元素收集到Map中,就稍微麻烦一点。因为对于每个元素,添加到Map时需要key和value,因此,我们要指定两个映射函数,分别把元素映射为key和value:public class Main { public static void main(String[] args) { Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft"); Map<String, String> map = stream .collect(Collectors.toMap( // 把元素s映射为key: s -> s.substring(0, s.indexOf(':')), // 把元素s映射为value: s -> s.substring(s.indexOf(':') + 1))); System.out.println(map); } }分组输出分组输出使用 Collectors.groupingBy(),它需要提供两个函数:一个是分组的key,这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组,第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List,上述代码运行结果如下:public class Main { public static void main(String[] args) { List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots"); Map<String, List<String>> groups = list.stream() .collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList())); System.out.println(groups); } }输出{ A=[Apple, Avocado, Apricots], B=[Banana, Blackberry], C=[Coconut, Cherry] }6、其他操作排序对Stream的元素进行排序十分简单,只需调用sorted()方法:public class Main { public static void main(String[] args) { List<String> list = List.of("Orange", "apple", "Banana") .stream() .sorted() .collect(Collectors.toList()); System.out.println(list); } }去重对一个Stream的元素进行去重,没必要先转换为Set,可以直接用distinct():List.of("A", "B", "A", "C", "B", "D") .stream() .distinct() .collect(Collectors.toList()); // [A, B, C, D] 截取截取操作常用于把一个无限的Stream转换成有限的Stream,skip()用于跳过当前Stream的前N个元素,limit()用于截取当前Stream最多前N个元素:List.of("A", "B", "C", "D", "E", "F") .stream() .skip(2) // 跳过A, B .limit(3) // 截取C, D, E .collect(Collectors.toList()); // [C, D, E]合并将两个Stream合并为一个Stream可以使用Stream的静态方法concat():Stream<String> s1 = List.of("A", "B", "C").stream(); Stream<String> s2 = List.of("D", "E").stream(); // 合并: Stream<String> s = Stream.concat(s1, s2); System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]flatMap如果Stream的元素的合集是:Stream<List<Integer>> s = Stream.of( Arrays.asList(1, 2, 3), Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9));而我们希望把上述Stream转换为Stream<Integer>,就可以使用flatMap():Stream<Integer> i = s.flatMap(list -> list.stream());因此,所谓flatMap(),是指把Stream的每个元素(这里是List)映射为Stream,然后合并成一个新的Stream:┌─────────────┬─────────────┬─────────────┐ │┌───┬───┬───┐│┌───┬───┬───┐│┌───┬───┬───┐│ ││ 1 │ 2 │ 3 │││ 4 │ 5 │ 6 │││ 7 │ 8 │ 9 ││ │└───┴───┴───┘│└───┴───┴───┘│└───┴───┴───┘│ └─────────────┴─────────────┴─────────────┘ │ │flatMap(List -> Stream) │ │ ▼ ┌───┬───┬───┬───┬───┬───┬───┬───┬───┐ │ 1 │ 2 │ 3 │ 4 │ 5 │ 6 │ 7 │ 8 │ 9 │ └───┴───┴───┴───┴───┴───┴───┴───┴───┘并行通常情况下,对Stream的元素进行处理是单线程的,即一个一个元素进行处理。但是很多时候,我们希望可以并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。把一个普通Stream转换为可以并行处理的Stream非常简单,只需要用parallel()进行转换:Stream<String> s = ... String[] result = s.parallel() // 变成一个可以并行处理的Stream .sorted() // 可以进行并行排序 .toArray(String[]::new);经过parallel()转换后的Stream只要可能,就会对后续操作进行并行处理。我们不需要编写任何多线程代码就可以享受到并行处理带来的执行效率的提升。分组// 将员工按薪资是否高于8000分组 Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000)); // 将员工按性别分组 Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex)); // 将员工先按性别分组,再按地区分组 Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));接合joining 可以将 stream 中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。List<String> list = Arrays.asList("A", "B", "C"); String string = list.stream().collect(Collectors.joining("-")); // 拼接后的字符串:A-B-C排序sorted,中间操作。有两种排序:sorted():自然排序,流中元素需实现 Comparable 接口sorted(Comparator com):Comparator 排序器自定义排序// 按工资升序排序(自然排序) List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName) .collect(Collectors.toList()); // 按工资倒序排序 List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()) .map(Person::getName).collect(Collectors.toList()); // 先按工资再按年龄升序排序 List<String> newList3 = personList.stream() .sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName) .collect(Collectors.toList()); // 先按工资再按年龄自定义排序(降序) List<String> newList4 = personList.stream().sorted((p1, p2) -> { if (p1.getSalary() == p2.getSalary()) { return p2.getAge() - p1.getAge(); } else { return p2.getSalary() - p1.getSalary(); } }).map(Person::getName).collect(Collectors.toList());总结Stream提供的常用操作有:转换操作:map(),filter(),sorted(),distinct();合并操作:concat(),flatMap();并行处理:parallel();聚合操作:reduce(),collect(),count(),max(),min(),sum(),average();其他操作:allMatch(), anyMatch(), forEach()。
-
SQL优化技巧 SQL优化是一个大家都比较关注的热门问题,无论在面试,还是工作中,都很有可能会遇到。1、避免使用 select *很多时候,我们写sql语句时,为了方便,喜欢直接使用 select * ,一次性查处所有列的数据。反例:select * from user where id=1;在实际业务场景中,可能我们需要的只是那么几个指定列的数据,并不需要全部。查了所有的数据,但是不用,就会白白浪费数据库资源,比如内存或者CPU。另外,多查出来的数据,通过网络 I/O 传输的过程中,也会增加数据传输的时间。还有一个问题就是,select * 不会走 覆盖索引 ,会出现大量的 回表 操作,从而导致查询sql的性能降低。应该如何优化,正例:select name,age from user where id=1;优化思路就是只查出需要用到的列,多余的列根本无需查出来。2、用union all 代替 unionSQL语句使用 union 关键字以后,可以获取重排后的数据。而如果使用 union all 关键字,可以获取所有数据,包含重复的数据。反例:(select * from user where id=1) union (select * from user where id=1);重排的过程是需要遍历,排序和比较的,它更加耗时,更消耗CPU资源。所以如果可以使用 union all 就尽量不使用 union。(select * from user where id=1) union all (select * from user where id=1);除非有一些特殊场景,比如话 union all 之后结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这是可以使用 union。3、小表驱动大表小表驱动大表的意思就是说,用小表的数据集驱动大表的数据集。具体怎么操作呢?假如现在有 order 和 user 两张表,其中 order 表有10000条数据,而 user 表只有100 条数据。这时如果想查看一下,所有有效用户成功下单的订单列表。可以使用 in 关键字实现:select * from order where user_id in (select id from user where status=1);或者使用 exists 关键字实现:select * from order where exists (select 1 from user where order.user_id = user.id and status=1);上面提到的这个场景其实使用 in 关键字去实现业务的话会更合适。为什么呢?因为如果 sql 语句中包含了 in 关键字,则它会优先执行in里面的 子查询语句,然后再执行in外面的语句。如果说in里面的数据量少,作为查询条件速度就会更快。而如果sql语句中包含了 exists 关键字,它会优先执行exists左边的语句(也就是主查询语句)。然后把它作为条件,去跟右边的语句匹配,如果匹配上了,就可以查询出数据,如果没有匹配上,数据就会被过滤掉。而在这个需求中 order表有10000条数据,user表只有100条数据。order表是大表,user表是小表。如果order表在左边,则用in关键字性能更好。总结:in 适合左边大表,右边小表exists 适合左边小表,右边大表无论是用 in 还是 exists 关键字,核心思想都是 小表驱动大表。4、批量操作如果你有一批数据经过业务处理之后,需要插入数据,该怎么办?反例:for(Order order : list){ orderMapper.insert(order); }在循环中逐条插入数据。insert into order(id,code,user_id) values(123,'001',100);该操作需要多次请求数据库,才能完成这批数据的插入。但是总所周知,在代码中每次远程请求数据库,都会有一定的性能消耗。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。那该如何优化?正例:orderMapper.insertBatch(list);提供一个批量插入数据的方法:insert into order(id,code,user_id) values(123,'001',100),(124,'002',100),(125,'001',101);这样做的话只会远程请求数据库一次,sql性能会有提升,数据量越多,性能提升越明显。但是需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在500以内。如果数据多于500,则分多批次处理。5、多用 limit有时需要查询某些数据中的第一条,比如:某个用户下的第一个订单,想看看他首单时间。反例:select id,create_date from order where user_id=123 order by create_date asc;根据用户id查询订单,按照下单时间排序,先查出该用户所有的订单数据,得到一个订单集合,然后在代码中获取第一个元素的数据,即首单的数据,然后就可以获取到首单时间。List<Order> list = orderMapper.getOrderList(); Order order = list.get(0);当你不知道怎么实现的时候,用这种方法为了现实功能是可以的,但是它效率不高,需要先查询出所有的数据,有点浪费资源。那么应该怎么优化?下面是正例:select id,create_date from order where user_id=123 order by create_date asc limit 1;使用 limit 1 , 只返回该用户下单时间最小的一条数据即可。另外,在删除或者修改数据时,为了防止误操作,导致删除或修改了不想干的数据,也可以在sql语句后面加上limit。例如:update order set status=0,edit_time=now(3) where id>=100 and id<200 limit 100;这样即使误操作,比如把id搞错了,也不会对太多的数据造成影响。6、in中值太多对于批量查询接口,我们通常会用 in 关键字过滤数据。比如:想通过指定的一些id批量查询出用户信息。sql语句如下:select id,name from category where id in (1,2,3...100000000);如果不做任何限制,该查询语句一次性可能会查出非常多的数据,很容易导致接口超时。这个时候该怎么呢?select id,name from category where id in (1,2,3...100000000) limit 500;也就是说可以在sql中对数据使用limit进行限制。不过我们更多的是要在业务代码中加限制,伪代码如下:public List<Category> getCategory(List<long> ids){ if((CollectionUtils.isEmpty(ids)){ return null; } if(ids.size() > 500){ throw new BusinessException("一次最多查询500条记录"); } return mapper.getCategoryList(ids); }还有一个方案就是:如果ids超过500条记录,可以分批用多线程去查询数据。每批只查询500条记录,最后把查询到的数据汇总到一起返回。不过这只是一个临时方案,不适合ids是在太多的场景。因为ids太多,即使能够快速查询出数据,但结果返回的数据量太大了,网络传输也是非常消耗性能的,接口性能始终好不到哪里。7、增量查询有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。反例:select * from user;如果直接获取所有的数据,然后同步过去。这样虽说非常方便,但是带来了一个非常大的问题,那就是如果数据很多的话,查询性能会非常差。这时该怎么办?正例:select * from user where id > #{lastId} and create_time >= #{lastCreateTime} limit 100;按id和时间升序,每次只同步一批数据,这一批数据只有100条记录。每次同步完成之后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用。最后通过这种增量查询的方式,能够提升单次查询的效率。8、高效分页有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。在mysql中分页一般用的 limit 关键字:select id,name,age from user limit 10,20;如果表中数据量少,用limit关键字做分页,没啥问题。但是如果表中数据量多,用它就会出现性能问题。比如现在分页参数变成了:select id,name,age from user limit 1000000,20;mysql会查到1000020条数据,然后丢弃前面的1000000条,只查后面的20条数据,这个是非常浪费资源的。那么,这种海量数据该怎么分页呢?优化sql:select id,name,age from user where id > 1000000 limit 20;先找到上次分页的最大id,然后利用id上的索引查询。不过该方案,要求uid是连续并且有序的。还能使用 betwwen 优化分页。select id,name,age from user where id between 1000000 and 1000020;需要注意的是between需要在唯一索引上分页,不然会出现每页大小不一致的问题。9、用连接查询代替子查询mysql中如果要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询子查询例子:select * from order where user_id in (select id from user where status=1);子查询语句可以通过 in 关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。(第3点小表驱动大表中有讲)子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。这时可以改成连接查询。具体例子如下:select o.* from order o inner join user u on o.user_id = u.id where u.status=1;10、join的表不宜过多根据阿里巴巴开发者手册的规定,join表的数量不应该超过3个。反例:select a.name,b.name.c.name,d.name from a inner join b on a.id = b.a_id inner join c on c.b_id = b.id inner join d on d.c_id = c.id inner join e on e.d_id = d.id inner join f on f.e_id = e.id inner join g on g.f_id = f.id如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。并且如果没有命中中,nested loop join 就是分别从两个表读一行数据进行两两对比,复杂度是 n^2。所以我们应该尽量控制join表的数量。正例:select a.name,b.name.c.name,a.d_name from a inner join b on a.id = b.a_id inner join c on c.b_id = b.id如果实现业务场景中需要查询出另外几张表中的数据,可以在a、b、c表中冗余专门的字段,比如:在表a中冗余d_name字段,保存需要查询出的数据。不过有些ERP系统,并发量不大,但业务比较复杂,需要join十几张表才能查询出数据。所以join表的数量要根据系统的实际情况决定,不能一概而论,尽量越少越好。11、join时要注意我们在涉及到多张表联合查询的时候,一般会使用join关键字。而join使用最多的是left join和inner join。left join : 求两个表的交集外加左表剩下的数据。inner join:求两个表交集的数据。使用 inner join 示例:select o.id,o.code,u.name from order o left join user u on o.user_id = u.id where u.status=1;如果两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。要特别注意的是在用 left join 关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。12、控制索引的数量众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。那么,问题来了,如果表中的索引太多,超过了5个该怎么办?这个问题要辩证的看,如果你的系统并发量不高,表中的数据量也不多,其实超过5个也可以,只要不要超过太多就行。但对于一些高并发的系统,请务必遵守单表索引数量不要超过5的限制。那么,高并发系统如何优化索引数量?能够建联合索引,就别建单个索引,可以删除无用的单个索引。将部分查询功能迁移到其他类型的数据库中,比如:Elastic Seach、HBase等,在业务表中只需要建几个关键索引即可。13、选择合理的字段类型char 表示固定字符串类型,该类型的字段存储空间是固定的,会浪费存储空间。alter table order add column code char(20) NOT NULL;varchar 表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间。alter table order add column code varchar(20) NOT NULL;如果是长度固定的字段,比如用户手机号,一般都是11位的,可以定义成char类型,长度是11字节。但如果是企业名称字段,假如定义成char类型,就有问题了。如果长度定义得太长,比如定义成了200字节,而实际企业长度只有50字节,则会浪费150字节的存储空间。如果长度定义得太短,比如定义成了50字节,但实际企业名称有100字节,就会存储不下,而抛出异常。所以建议将企业名称改成varchar类型,变长字段存储空间小,可以节省存储空间,而且对于查询来说,在一个相对较小的字段内搜索效率显然要高些。我们在选择字段类型时,应该遵循这样的原则:能用数字类型,就不用字符串,因为字符的处理往往比数字要慢尽可能使用小的类型,比如:用bit存布尔值,用tinyint存枚举值等长度固定的字符串字段,用char类型长度可变的字符串字段,用varchar类型金额字段用decimal,避免精度丢失问题。还有很多原则,这里不一一列举。14、提升group by的效率我们有很多业务场景需要使用 group by 关键字,它主要的功能是去重和分组。通常它会跟 having 一起配合使用,表示分组后再根据一定的条件过滤数据。反例:select user_id,user_name from order group by user_id having user_id <= 200;这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?select user_id,user_name from order where user_id <= 200 group by user_id;使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。其实这是一种思路,不仅限于group by的优化。我们的sql语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升sql整体的性能。15、索引优化sql优化当中,有一个非常重要的内容就是:索引优化。很多时候sql语句,走了索引,和没有走索引,执行效率差别很大。所以索引优化被作为sql优化的首选。索引优化的第一步是:检查sql语句有没有走索引。那么,如何查看sql走了索引没?可以使用 explain 命令,查看mysql的执行计划。例如:explain select * from 'order' where code='002';结果:通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:说实话,sql语句没有走索引,排除没有建索引之外,最大的可能性是索引失效了。下面说说索引失效的常见原因:如果不是上面的这些原因,则需要再进一步排查一下其他原因。